1.Kafka基本概念
- broker 服务节点,多个broke构成kafka集群,主要负责消息接收和存储
- topic 可以理解成一个通道,不同topic之间互相隔离,因此可用于隔离不同业务。例如用户和订单使用两个不同topic来完成消息隔离。
- paritition 分区,建立在broke的基础之上,通常在一个topic建立不同的分区存储在不同的broke上。一个topic对应一个分区就是生产者-消费者模式,一个topic对应多个分区才是发布-订阅模式。可在不同broker创建相同的分区,有主副之分(Replication 副本),实现数据冷备份。
- Producer 生产消息的客户端
- Consumer 消费消息的客户端
- Consumer Group 消费者组,一个组下存在多个消费者。一个消费者消费同一个topic下多个partition,但是一个partition最多被一个消费者组中的一个消费者消费
- Group Id 用于区分不同的消费者组
- ConsumerGroup Coordinator
- AR(Assigned Replicas): 所有的副本 AR
- ISR (In-Sync Replicase): ISR是AR的一个子集,即所有和主副本保持同步的副本集合, offset差距在一定范围内;
- OSR(Out-of-Sync Replicase): 和ISR相反,offset超过一定的范围,同时ISR+OSR=AR,同时失效的副本也可以通过追上主副本来重新进入ISR;
- LEO(Log End Offset): LEO是下一个消息将要写入的offset偏移,在LEO之前的消息都已经写入日志了,每一个副本都有一个自己的LEO。
- HW(High Watermark): 所有和主副本保持同步的副本中,最小的那个LEO就是HW,这个offset意味着在这之前的消息都已经被所有的ISR写入日志了,消费者可以拉取了,这时即使主副本失效其中一个ISR副本成为主副本,对于消费者而言消息也不会丢失。
2.Kafka集成SpringBoot
对于Kafka的配置可以采用配置文件形式的配置,也可以采用配置类的方式
2.1配置文件
spring:
kafka:
bootstrap-servers: 10.100.113.38:9092
producer: #生产者
retries: 3
properties:
partitioner:
class: com.wizard.kafka.partition.MyPartitioner #配置自定义分区
interceptor:
classes: com.wizard.kafka.interceptor.MyInterceptors #配置自定义拦截器
batch-size: 16384
buffer-memory: 33554432
ack: 1
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: "myGroup"
enable-auto-commit: false
auto-offset-reset: earliest
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
max-poll-records: 500
listener:
ack-mode: manual_immediate
#manual_immediate和manual的区别:前者是一条消息处理完就会提交 后者是处理一批消息后才会提交
#kafka通常使用一批一批(500条)的数据进行消费
2.2配置类
@Configuration
public class KafkaConfig {
@Bean
public ProducerFactory producerFactory(){
return new DefaultKafkaProducerFactory(produceConfig());
}
@Bean
public Map<String, Object> produceConfig(){
Map<String, Object> properties = new HashMap<>();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.100.113.38:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//默认是32M 缓冲池
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
//默认使用16kb
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);
//自定义分区
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());
//自定义拦截器
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, List.of(MyInterceptors.class.getName()));
return properties;
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate(){
return new KafkaTemplate<>(producerFactory());
}
}
上述我只是配置了生产者,消费者的配置和上述类似,只是有些参数是有区别的。对于生产者而言,是想获取KafkaTempalate这个对象,这个对象需要DefaultKafkaProducerFactory来构建生成,这个工厂中开发者要完成一些属性的配置。
Note:说明一点的是,上述的自定义分区生效要求在发送数据时没有指定分区,如果指定了分区数的话那么自定义分区就不会生效,另外同一个拦截器添加多次时会执行多次。
3.自定义配置方式
3.1自定义配置拦截器
public class MyInterceptors implements ProducerInterceptor {
//拦截器 可以对生产者的消息数据进行加工
@Override
public ProducerRecord onSend(ProducerRecord record) {
log.info("MyInterceptors ======, record: {}", record);
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
spring:
kafka:
producer: #生产者
properties:
interceptor:
classes: com.wizard.kafka.interceptor.MyInterceptors #配置自定义拦截器
3.2 自定义配置分区
实现Partitioner接口自定义分区,如果没有kafka会提供响应的分区策略。
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
log.info("MyPartitioner, topic: {}", topic);
//根据参数返回对应的分区 此处是对任何topic消息体中的数据为Frist全部放在第一个分区上
int partition = 0;
if("First".equals(value.toString())){
partition = 1;
}
return partition;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
spring:
kafka:
producer: #生产者
properties:
partitioner:
class: com.wizard.kafka.partition.MyPartitioner #配置自定义分区器的全路径名
根据上面的配置方式可以自定义配置key/value的序列化器和反序列器等
4.生产者原理
在正式讲述生产者原理之前,先通过流程图来了解一下生产者创建消息后发送到Kafka集群。
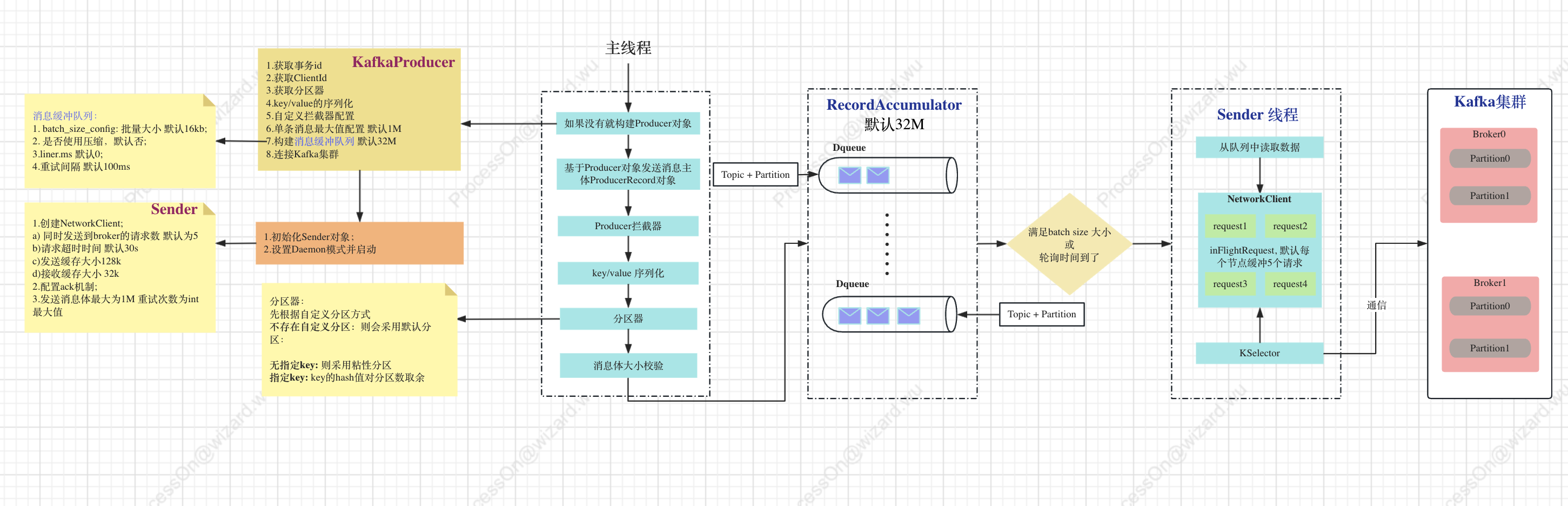
主要流程如下:
- 初始化KafkaProducer对象,完成Sender线程的创建;
- 生产者产生ProducerRecord对象消息,经过拦截器、序列化器、分区器到达RecordAccumulator的队列中;
- RecordAccumulator是生产者主线程和Sender线程的桥梁,在消息到达队列中后满足条件会唤醒Sender线程。Note:RecordAccumulator中的Dequeu是和topic和partition构成映射关系的;
- Sender线程将消息通过NetWorkClient发送到Kafka集群,其中使用的KSelector的IO通信方式。
4.1 Kafka初始化Producer
//kafka生产者的消息对象
public class ProducerRecord<K, V> {
private final String topic; //需要指定的往哪个topic发送消息
private final Integer partition; //指定往哪个分区发送消息 可选
private final Headers headers; //用于存储和业务数据无关的 例如路由id traceId方法问题排查
private final K key; //业务key 可选
private final V value; //消息主体
private final Long timestamp; //记录消息产生的时间 可用于监控消息延迟情况
}
//初始化Kafka的Producer,发送消息要基于该对象进行发送 这个对象是单例的
//org.apache.kafka.clients.producer.KafkaProducer#KafkaProducer
KafkaProducer(Map<String, Object> configs,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors interceptors,
Time time) {
//构建生产者的配置, configs是从开发者的配置中加载来的
ProducerConfig config = new ProducerConfig(ProducerConfig.addSerializerToConfig(configs, keySerializer,valueSerializer));
try {
Map<String, Object> userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = time;
//获取事务id 如果用到事务必须要有事务id 没有就会报错
String transactionalId = userProvidedConfigs.containsKey(ProducerConfig.TRANSACTIONAL_ID_CONFIG) ? (String) userProvidedConfigs.get(ProducerConfig.TRANSACTIONAL_ID_CONFIG) : null;
//客户端标识 用于标识发送给kafka集群的消息是来自哪个客户端
this.clientId = buildClientId(config.getString(ProducerConfig.CLIENT_ID_CONFIG), transactionalId);
LogContext logContext;
if (transactionalId == null)
logContext = new LogContext(String.format("[Producer clientId=%s] ", clientId));
else
logContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));
log = logContext.logger(KafkaProducer.class);
log.trace("Starting the Kafka producer");
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG)).timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS) .recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricTags);
//用于监控kafka运行指标
List<MetricsReporter> reporters = config.getConfiguredInstances(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG, MetricsReporter.class, Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
reporters.add(new JmxReporter(JMX_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time);
//获取分区器
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
//key序列化器
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,Serializer.class);
this.keySerializer.configure(config.originals(), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
//value的序列化器
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer.configure(config.originals(), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
// load interceptors and make sure they get clientId
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
ProducerConfig configWithClientId = new ProducerConfig(userProvidedConfigs, false);
//加载自定义的拦截器
List<ProducerInterceptor<K, V>> interceptorList = (List) configWithClientId.getConfiguredInstances(
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptor.class);
if (interceptors != null)
this.interceptors = interceptors;
else
this.interceptors = new ProducerInterceptors<>(interceptorList);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer, valueSerializer, interceptorList, reporters);
//单条消息大小 默认1M
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
//Buffer内存大小 默认32M
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG
//数据压缩类型 默认是none
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
this.transactionManager = configureTransactionState(config, logContext, log);
int deliveryTimeoutMs = configureDeliveryTimeout(config, log);
this.apiVersions = new ApiVersions();
//消息缓冲区对象 默认32M大小
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), //批次大小 默认16kb
this.compressionType, //压缩类型 默认none
lingerMs(config), //liner.ms 默认0 建议不要设置成0
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME)); //内存池大小32M
//获取kafka集群地址
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG),
config.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG));
if (metadata != null) {
this.metadata = metadata;
} else {
this.metadata = new ProducerMetadata(retryBackoffMs,
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
this.metadata.bootstrap(addresses);
}
this.errors = this.metrics.sensor("errors");
//初始化后台线程sender
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
//创建守护线程 用户发送数据到kafka
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
//启动线程 该线程用于发送数据到broker
this.ioThread.start();
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka producer started");
} catch (Throwable t) {
// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121
close(Duration.ofMillis(0), true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t);
}
}
KafkaProducer是一个单例对象,初始化是在第一条消息发送时发送的,不是在服务器启动的时候初始化的,因此可以理解成一种懒加载的方式。初始化的主要参数和过程如下:
- 获取来自开发者的自定义配置;
- 获取分区器、key/value序列化器、拦截器,均可自定义;
- 设置单条消息最大值(默认1M)、BufferPool的内存大小(默认32M)、压缩类型(默认none);
- 初始化消息缓存区对象RecordAccumulator,包含BufferPool,批次大小默认16kb,liner.ms默认0
- 获取Kafka集群数据并获取metadata数据;
- 初始化Sender线程并启动;
上述两个参数batch.size和liner.ms要根据实际来设置,例如实践中消息大小普遍在50kb左右,这时就要调整batch.size,否则就不能达到批处理的效果。liner.ms可设置成10ms-500ms之间。
4.2 Kafka初始化Sender线程
// 初始化Sender线程 Sender线程实现了Runnable接口的
Sender newSender(LogContext logContext, KafkaClient kafkaClient, ProducerMetadata metadata) {
//同时发送到broker的请求数
int maxInflightRequests = configureInflightRequests(producerConfig, transactionManager != null);
//sender线程等待broker相应的超时时间 默认30s 超时会重试
int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(producerConfig, time);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
//创建客户端对象 也就是发送消息到broker的服务
KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient(
new Selector(producerConfig.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG),
this.metrics, time, "producer", channelBuilder, logContext),
metadata,
clientId,
maxInflightRequests,
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MS_CONFIG),
producerConfig.getLong(ProducerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG),
producerConfig.getInt(ProducerConfig.SEND_BUFFER_CONFIG), //发送缓冲区大小 128k
producerConfig.getInt(ProducerConfig.RECEIVE_BUFFER_CONFIG), //接收缓冲区大小 32k
requestTimeoutMs,
ClientDnsLookup.forConfig(producerConfig.getString(ProducerConfig.CLIENT_DNS_LOOKUP_CONFIG)),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
int retries = configureRetries(producerConfig, transactionManager != null, log);
//ack 机制 详细见下文
short acks = configureAcks(producerConfig, transactionManager != null, log);
return new Sender(logContext,
client,
metadata,
this.accumulator,
maxInflightRequests == 1,
producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
time,
requestTimeoutMs,
producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
}
Sender线程中配置了很多参数,例如:
- KafkaClient:发送请求到broke的客户端:
- accumulator:消息缓存区;
- 发送客户端对象:发送缓冲区大小128kb,接收为32kb;
- ack机制
- 重试机制
还有很多,接下来对于生产者的ACK机制的说明:
生产者中的ACK配置
在同步发送消息时,发送方在等待ACK返回之前一直处于阻塞状态,那么集群什么时候返回ACK呢?ACK的配置
- ack=0,立即返回,不需要等待broke是否确认收到消息,就可以继续发送下一条;
- ack=1,至少等待leader成功将数据写入log再返回,这是不管其他的follow节点。这时如果leader节点挂了会导致消息数据丢失;
- ack=-1或者all,等待所有节点成功将数据写入log然后返回,此处包括follow节点。性能很差除非是和钱相关的业务min.insync.replicas=2(推荐要大于1) 也就是至少有一个主节点和一个从节点完成成功将数据写入log
4.3 发送消息到RecordAccumulator
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
// first make sure the metadata for the topic is available
ClusterAndWaitTime clusterAndWaitTime;
try {
//获取当前topic的最新元数据
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
//序列化key
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
//异常代码去除
}
byte[] serializedValue;
try {
//序列化value
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
//异常代码去除
}
//获取分区值
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
//确保序列化后消息大小不能超过某个值,如果使用了压缩算法 则大小为压缩后的大小
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
if (log.isTraceEnabled()) {
log.trace("Attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
//拦截器的函数回调
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional()) {
transactionManager.failIfNotReadyForSend();
}
//往缓存队列中追加数据
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true);
if (result.abortForNewBatch) {
int prevPartition = partition;
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false);
}
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
//如果上述的添加数据到队列中 存在满了或者新的队列创建 则触发sender线程发送数据到broker
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, tp, e);
throw e;
}
}
发送消息数据到Accumulator缓存区步骤:
- 获取最新的kafka集群的数据;
- 获取分区值、key/value序列化器、拦截器;
- 往缓存队列中添加数据,如果队列满了或者新的队列创建,会触发Sender线程发送数据到Kafka集群;
获取分区值的逻辑:如果指定了key,取 key 的 hash 值,然后与 partition 总数取模,得到目标 partition 编号,这样可以保证同一 key 的 message 进入同一 partition;如果未指定key,则StickyPartitionCache.partition() 方法计算目标 partition。StickyPartitionCache 主要实现的是”黏性选择”,就是尽可能的先往一个 partition 发送 message,这样可以让某个队列短时间填满,可以不用等到周期时间再去发送消息。
在将record(消息)加入到Accumulator中时,会根据record的topic partition(此时会指定或者根据key来计算出tp)找到RecordBatch队列。如果不存在,就新建一个队列,在队列中取出最后一个RecordBatch,如果这个batch还有空间,就把record新追加到缓存后面,这样1个batch可能会有多个record,如果batch空间不够,就新创建一个batch,重新分配一个Max(16k, recordsize)的buffer,如果这个record超过16k,则这个batch中只会保存这1个record。
下面是添加数据到缓存中的逻辑
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
Callback callback,
long maxTimeToBlock,
boolean abortOnNewBatch) throws InterruptedException {
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
//为topic的partition创建一个队列
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new KafkaException("Producer closed while send in progress");
//尝试追加数据到队列中 第一次执行时 是不能添加成功的
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null)
return appendResult;
}
// we don't have an in-progress record batch try to allocate a new batch
if (abortOnNewBatch) {
// Return a result that will cause another call to append.
return new RecordAppendResult(null, false, false, true);
}
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
//批次大小默认16kb,和压缩后的消息体进行比较, 该size最小为16kb
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
//在缓冲区为批次申请内存大小
buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new KafkaException("Producer closed while send in progress");
//同时此处第一次执行也是添加失败的 下一次执行的话会会在队列的最后一个批次对象取数据 如果该批次空间可以就直接把消息数据存入
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
return appendResult;
}
//封装内存buffer
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
//再次封装消息
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, time.milliseconds());
FutureRecordMetadata future = Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers,callback, time.milliseconds()));
//在队列的尾端添加消息数据 头是用于发送数据
dq.addLast(batch);
incomplete.add(batch);
// Don't deallocate this buffer in the finally block as it's being used in the record batch
buffer = null;
//当前dp已经添加了一条数据或者batch已经满了
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false);
}
} finally {
if (buffer != null)
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}
上述代码有两个加了synchronized的地方,这是因为减少程序运行阻塞提高并发。其中有个申请内存操作是比较耗时的,实际上内部也是加锁的。
RecordAccumulator 相关的核心内容,它是业务线程和 Sender 线程之间数据的中转站,生产者先将消息添加到RecordAccumulator 缓冲区,主要步骤如下:
- 根据topic和partition获取一个队列,如果不存在就会初始化一个;
- 尝试往队列中添加消息,一般第一次不能添加成功,因为刚刚初始化的队列为空的;
- 在缓冲区为批次对象申请内存大小;
- 封装消息体后在队列的尾端添加消息数据,队列头端用于Sender线程取数据发送到Kafka服务;
- 释放缓存区内存大小;
在步骤1中根据Topic和Partition获取一个队列,该结构是一个CopyOnWriteMap,这是Kafka自己设计的一个线程安全的map,不是JUC包下面的,仅对写操作加了Synchronize的修饰,读操作没有做任何处理。其内部实际上维护的一个HashMap,这种适合读多写少的场景,数量是所有topic的所有partition的。

4.4 Sender线程发送消息到Broker
//Sender线程的run方法会调用如下方法
void runOnce() {
if (transactionManager != null) {
try {
transactionManager.resetProducerIdIfNeeded();
if (!transactionManager.isTransactional()) {
// this is an idempotent producer, so make sure we have a producer id
maybeWaitForProducerId();
} else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) {
transactionManager.transitionToFatalError(
//
} else if (maybeSendAndPollTransactionalRequest()) {
return;
}
// do not continue sending if the transaction manager is in a failed state or if there
// is no producer id (for the idempotent case).
if (transactionManager.hasFatalError() || !transactionManager.hasProducerId()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, time.milliseconds());
return;
} else if (transactionManager.hasAbortableError()) {
accumulator.abortUndrainedBatches(transactionManager.lastError());
}
} catch (AuthenticationException e) {
//
}
}
//上述主要是用于处理事务相关的
long currentTimeMs = time.milliseconds();
//发送消息 该方法详细见下文
long pollTimeout = sendProducerData(currentTimeMs);
//获取从broke端的响应结果
client.poll(pollTimeout, currentTimeMs);
}
上述主要是Sender线程调用sendProducerData方法,该方法内容如下:
private long sendProducerData(long now) {
//获取Kafka集群的元数据
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send
//获取accumulator是否有准备好的数据 ready方法详细内容见下文
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//如果存在topic中没有分区的主节点的话 那么就会记录
if (!result.unknownLeaderTopics.isEmpty()) {
// The set of topics with unknown leader contains topics with leader election pending as well as
// topics which may have expired. Add the topic again to metadata to ensure it is included
// and request metadata update, since there are messages to send to the topic.
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
log.debug("Requesting metadata update due to unknown leader topics from the batched records: {}",
result.unknownLeaderTopics);
//调用该方法会让metadata打上一个更新的标记 不会阻塞
this.metadata.requestUpdate();
}
//删除没有准备好的节点数据(broke节点)
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
}
}
// create produce requests
//对每个broker节点发送的数据进行分组 同一个节点上 数据放在一起 将请求数降到节点数量
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
//....... 删除部分代码
//发送数据
sendProduceRequests(batches, now);
return pollTimeout;
}
步骤1: 获取集群元数据信息,第一次进来是没有获取的,只会触发获取的条件,在执行最后的client.poll()的时候才会完成真正的数据发送
步骤2: 根据元数据信息的集群信息,获取accumulator中哪些batches已经ready
步骤3: 校验已经ready的数据的元数据信息是否ready,是否有某一个partition还没有找到leader等
步骤4: 判断NetworkClient是否已经建立连接
步骤5: 根据broker进行数据分组,因为同一个broker可能有很多个partition,进行聚合
步骤6: 发送超时和过期数据的处理
步骤7: 聚合数据,调用NetworkClient完成网络操作,NetworkClient底层依赖于Select来完成
在步骤5中会根据batches的ConcurrentMap会重新数据分组,batches中是根据topic和partition分组,重新分组是根据broke来分组。因为在一个broke中会存在多个topic的partition的主节点,因此在发送的消息中如果存在两个topic的leader的Partition在同一个broke中,根据broke来进行分组,会将这两个topic的消息放在一组,只要发送一次请求即可。
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
//此处的nodes需要用于结果返回
Set<Node> readyNodes = new HashSet<>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
Set<String> unknownLeaderTopics = new HashSet<>();
boolean exhausted = this.free.queued() > 0;
//遍历批次中的每一天消息数据
for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) {
Deque<ProducerBatch> deque = entry.getValue();
synchronized (deque) {
ProducerBatch batch = deque.peekFirst();
if (batch != null) {
//获取当前批次中的topic分区
TopicPartition part = entry.getKey();
//获取该topic下的分区主节点
Node leader = cluster.leaderFor(part);
if (leader == null) {
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !isMuted(part, nowMs)) {
long waitedTimeMs = batch.waitedTimeMs(nowMs);
//attempts大于0则是进行重试 重试&&等待时间小于重试时间 默认100ms
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
//如果是重试且等待时间小于重试时间 则设置等待时间为重试时间 否则赋值为批次的周期时间linger.ms
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
//批次大小满足发送条件:1.队列中存在批次;2.批次已经满了
boolean full = deque.size() > 1 || batch.isFull();
//如果超时情况 也是要发送
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
//如果可以发送 将主节点添加到set集合中
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics);
}
InflightRequests集合的作用就是缓存已经发送出去但还没有收到响应的ClientRequest 请求集合。底层是通过 ReqMap<string, Deque
Kafka在发送请求是将批量消息放在一起发送,那么响应数据中就会面临一个问题:粘包
解决粘包拆包问题的方法:
(1)消息定长;
(2)增加特殊字符进行分割,比如每条数据末尾都添加一个换行符;
(3)自定义协议,例如 len + data,其中len是代表data的字节长度;
Kafka中解决粘包的问题是通过第三种的方式。
5.消费者原理
5.1消费者对象初始化
private KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
try {
//消费者组的重平衡的配置
GroupRebalanceConfig groupRebalanceConfig = new GroupRebalanceConfig(config,
GroupRebalanceConfig.ProtocolType.CONSUMER);
//消费者组的groupId的赋值 (myGroup)
this.groupId = groupRebalanceConfig.groupId;
//组内的每一个消费者身份标识 (consumer-myGroup-1)
this.clientId = buildClientId(config.getString(CommonClientConfigs.CLIENT_ID_CONFIG), groupRebalanceConfig);
//log相关处理
LogContext logContext;
if (groupRebalanceConfig.groupInstanceId.isPresent()) {
logContext = new LogContext("[Consumer instanceId=" + groupRebalanceConfig.groupInstanceId.get() +
", clientId=" + clientId + ", groupId=" + groupId + "] ");
} else {
logContext = new LogContext("[Consumer clientId=" + clientId + ", groupId=" + groupId + "] ");
}
this.log = logContext.logger(getClass());
boolean enableAutoCommit = config.getBoolean(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG);
if (groupId == null) { // overwrite in case of default group id where the config is not explicitly provided
if (!config.originals().containsKey(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG))
enableAutoCommit = false;
else if (enableAutoCommit)
throw new InvalidConfigurationException(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG + " cannot be set to true when default group id (null) is used.");
} else if (groupId.isEmpty())
log.warn("Support for using the empty group id by consumers is deprecated and will be removed in the next major release.");
//请求超时时间:客户端(消费者)等待服务端(Broke)响应最长时间 默认为30s 如果超时之前没有响应,客户端在必要时会重新发送
this.requestTimeoutMs = config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG);
//
this.defaultApiTimeoutMs = config.getInt(ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG);
this.time = Time.SYSTEM;
this.metrics = buildMetrics(config, time, clientId);
//重试时间 100毫秒
this.retryBackoffMs = config.getLong(ConsumerConfig.RETRY_BACKOFF_MS_CONFIG);
// load interceptors and make sure they get clientId
Map<String, Object> userProvidedConfigs = config.originals();
userProvidedConfigs.put(ConsumerConfig.CLIENT_ID_CONFIG, clientId);
//获取消费者的拦截器
List<ConsumerInterceptor<K, V>> interceptorList = (List) (new ConsumerConfig(userProvidedConfigs, false)).getConfiguredInstances(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
ConsumerInterceptor.class);
this.interceptors = new ConsumerInterceptors<>(interceptorList);
//key和value的反序列化器
if (keyDeserializer == null) {
this.keyDeserializer = config.getConfiguredInstance(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.keyDeserializer.configure(config.originals(), true);
} else {
config.ignore(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG);
this.keyDeserializer = keyDeserializer;
}
if (valueDeserializer == null) {
this.valueDeserializer = config.getConfiguredInstance(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, Deserializer.class);
this.valueDeserializer.configure(config.originals(), false);
} else {
config.ignore(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG);
this.valueDeserializer = valueDeserializer;
}
//offset重置策略:latest-从最近没有消费的开始; earliest-从最早的开始第一条消息产生的地方; none-不做任何消息消费
OffsetResetStrategy offsetResetStrategy = OffsetResetStrategy.valueOf(config.getString(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG).toUpperCase(Locale.ROOT));
this.subscriptions = new SubscriptionState(logContext, offsetResetStrategy);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keyDeserializer,
valueDeserializer, metrics.reporters(), interceptorList);
//消费者元数据
this.metadata = new ConsumerMetadata(retryBackoffMs, //重试时间
config.getLong(ConsumerConfig.METADATA_MAX_AGE_CONFIG),
!config.getBoolean(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG), //是否允许访问系统主题 默认不允许
config.getBoolean(ConsumerConfig.ALLOW_AUTO_CREATE_TOPICS_CONFIG), //是否允许自动创建topic 默认为true
subscriptions, logContext, clusterResourceListeners);
//获取kafka集群的ip和端口号
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(
config.getList(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG), config.getString(ConsumerConfig.CLIENT_DNS_LOOKUP_CONFIG));
this.metadata.bootstrap(addresses);
String metricGrpPrefix = "consumer";
FetcherMetricsRegistry metricsRegistry = new FetcherMetricsRegistry(Collections.singleton(CLIENT_ID_METRIC_TAG), metricGrpPrefix);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config, time);
IsolationLevel isolationLevel = IsolationLevel.valueOf(
config.getString(ConsumerConfig.ISOLATION_LEVEL_CONFIG).toUpperCase(Locale.ROOT));
Sensor throttleTimeSensor = Fetcher.throttleTimeSensor(metrics, metricsRegistry);
int heartbeatIntervalMs = config.getInt(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG);
ApiVersions apiVersions = new ApiVersions();
//创建通信客户端
NetworkClient netClient = new NetworkClient(
new Selector(config.getLong(ConsumerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), metrics, time, metricGrpPrefix, channelBuilder, logContext),
this.metadata,
clientId,
100, // a fixed large enough value will suffice for max in-flight requests
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MS_CONFIG), //重试时间 默认50毫秒
config.getLong(ConsumerConfig.RECONNECT_BACKOFF_MAX_MS_CONFIG), //最大连接重试时间 1秒
config.getInt(ConsumerConfig.SEND_BUFFER_CONFIG), //发送缓存大小 默认128kb
config.getInt(ConsumerConfig.RECEIVE_BUFFER_CONFIG), //接收缓存大小 64kb
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
ClientDnsLookup.forConfig(config.getString(ConsumerConfig.CLIENT_DNS_LOOKUP_CONFIG)),
time,
true,
apiVersions,
throttleTimeSensor,
logContext);
//消费者客户端
this.client = new ConsumerNetworkClient(
logContext,
netClient,
metadata,
time,
retryBackoffMs,
config.getInt(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG),
heartbeatIntervalMs); //Will avoid blocking an extended period of time to prevent heartbeat thread starvation
//分区策略
this.assignors = getAssignorInstances(config.getList(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG), config.originals());
// no coordinator will be constructed for the default (null) group id
this.coordinator = groupId == null ? null :
new ConsumerCoordinator(groupRebalanceConfig,
logContext,
this.client,
assignors,
this.metadata,
this.subscriptions,
metrics,
metricGrpPrefix,
this.time,
enableAutoCommit,
config.getInt(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG),
this.interceptors);
//消费者抓取数据的配置:
this.fetcher = new Fetcher<>(
logContext,
this.client,
config.getInt(ConsumerConfig.FETCH_MIN_BYTES_CONFIG), //最少抓取数据大小: 1byte
config.getInt(ConsumerConfig.FETCH_MAX_BYTES_CONFIG), //最多抓取 50M
config.getInt(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG), //抓取最大的等待时间 500ms
config.getInt(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG),
config.getInt(ConsumerConfig.MAX_POLL_RECORDS_CONFIG), //最多一次处理数据的个数:500
config.getBoolean(ConsumerConfig.CHECK_CRCS_CONFIG),
config.getString(ConsumerConfig.CLIENT_RACK_CONFIG),
this.keyDeserializer,
this.valueDeserializer,
this.metadata,
this.subscriptions,
metrics,
metricsRegistry,
this.time,
this.retryBackoffMs,
this.requestTimeoutMs,
isolationLevel,
apiVersions);
this.kafkaConsumerMetrics = new KafkaConsumerMetrics(metrics, metricGrpPrefix);
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka consumer initialized");
} catch (Throwable t) {
// call close methods if internal objects are already constructed; this is to prevent resource leak. see KAFKA-2121
close(0, true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka consumer", t);
}
}
初始化消费者的过程如下:
- 当前所在的消费者组采用的重平衡的配置,将该配置赋给消费者;
- 提供groupId和clientId的唯一标识给消费者;
- 请求broke服务器最多等待30s(默认),第一次没有连接上,间隔100ms(默认)重新连接;
- 和生产者一样,拦截器处理,key/value的反序列化;
- 设置offset的重置策略,有三种 latest(默认 )、earliest、none;
- 初始化消费者元数据,包括消费重试时间,是否允许创建主题,是否允许访问系统主题等;
- 获取kafka集群数据,包括ip和端口号;
- 初始化数据通信客户端,参数包括重试时间(50ms)、最大连接重试时间(100ms)、发送缓存(默认128kb)和接收缓存(默认64kb);
- 利用通信客户端初始化消费者客户端;
- 获取分区策略;
- 初始化消费者消费消息配置,最少1byte,最多50M,最大等待500ms,最多一次处理数据500条,上述均为默认;
分区分配的策略
range:消费者按序分类,例如有0 1 2 3 4 5 6个分区但是只有三台消费者A B C,这时A 会负责0 1 2,B负责34, C负责56;
roundRobin:范围分区 上述的话就是A负责0, 3, 6三个分区 B负责1, 4 C负责2, 5
sticky:粘合策略
- 尽可能保证之前的分区分配;保证reblance是不用重新进行分区分配
- 分区的分配尽可能均匀
上述的前两种策略均会产生全局的分配重分配策略,导致在reblance时导致系统处于停滞状态,sticky只会对于发生变化的分区或者消费者进行相应的处理。
CooperativeSticky:协调式粘合策略
和上述的sticky策略差不多,但是它在此基础上是用的RebalanceProtocol.COOPERATIVE协议,渐进式的重平衡。StickyAssignor仍然是基于eager协议,分区重分配时候,都需要consumers先放弃当前持有的分区,重新加入consumer group;而CooperativeStickyAssignor基于cooperative协议,该协议将原来的一次全局分区重平衡,改成多次小规模分区重平衡。
自定义分区策略:实现该接口ConsumerPartitionAssignor
默认是range+cooperativeSticky
5.2消费者订阅主题
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
//主题集合为空直接抛异常
if (topics == null)
throw new IllegalArgumentException("Topic collection to subscribe to cannot be null");
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
this.unsubscribe();
} else {
//主题集合中存在空的topic直接抛异常
for (String topic : topics) {
if (topic == null || topic.trim().isEmpty())
throw new IllegalArgumentException("Topic collection to subscribe to cannot contain null or empty topic");
}
throwIfNoAssignorsConfigured();
fetcher.clearBufferedDataForUnassignedTopics(topics);
log.info("Subscribed to topic(s): {}", Utils.join(topics, ", "));
//如果订阅了主题 需要更新新的主题 订阅主题时注册了监听器 主要用于监听消费者是否发生变化进行重平衡 主要是根据心跳来检测变化
if (this.subscriptions.subscribe(new HashSet<>(topics), listener))
metadata.requestUpdateForNewTopics();
}
} finally {
release();
}
}
订阅主题主要是判断主题为空的判断很严格,同时订阅主题时会注册监听器,用来消费者变化时进行重平衡。
5.3消费者获取数据
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// if data is available already, return it immediately
//先去队列中获取一些数据 存在数据直接返回
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
//如果第一次没有获取到数据 重新发送获取数据请求
fetcher.sendFetches();
// We do not want to be stuck blocking in poll if we are missing some positions
// since the offset lookup may be backing off after a failure
// NOTE: the use of cachedSubscriptionHashAllFetchPositions means we MUST call
// updateAssignmentMetadataIfNeeded before this method.
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
Timer pollTimer = time.timer(pollTimeout);
client.poll(pollTimer, () -> {
// since a fetch might be completed by the background thread, we need this poll condition
// to ensure that we do not block unnecessarily in poll()
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
// after the long poll, we should check whether the group needs to rebalance
// prior to returning data so that the group can stabilize faster
if (coordinator != null && coordinator.rejoinNeededOrPending()) {
return Collections.emptyMap();
}
//在上述方法sendFetches方法中 已经将响应数据放到了消息队列了 此处会去该消息队列中拉取数据
//取数据最多500条消息 或者 队列中数据处理完了
return fetcher.fetchedRecords();
}
//处理完数据后经过拦截 处理
上来就去对completedFetches的队列中获取数据,如果存在数据直接返回,如果不存在则会再次发送获取数据的请求。
消费者自动提交和手动提交offset设置:
自动提交:将enable.auto.commit设置为true,那么消费者会在poll方法调用后每隔五秒(由auto.commit.interval.ms指定)提交一次位移。 缺点:重复消费。由于存在时间间隔,如果某个消费者消费了消息由于发生重平衡导致消息被其他消费者再次消费。
手动提交:将enable.auto.commit设置为true。 异步使用KafkaConsumer的commitAsync(),同步使用KafkaConsumer的commitSync(),另外Acknowledgment的acknowledge()是默认同步的。
1.同步提交,消费完消息后,提交offset等待结果返回,消费者一直处于阻塞状态;
2.异步提交,消费完消息后,提交offset时提供一个callback函数给broke方进行回调;
在手动提交模式下,如果没有进行手动提交会重试,导致重复消费
从源码角度比较同步提交offset和异步提交offset的区别:
//同步提交的核心代码
public boolean commitOffsetsSync(Map<TopicPartition, OffsetAndMetadata> offsets, Timer timer) {
invokeCompletedOffsetCommitCallbacks();
if (offsets.isEmpty())
return true;
//上来就是一个do-while的循环 退出条件:1.成功提交;2.失败并不能重试;3.失败可重试但是重试时间到了
do {
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
RequestFuture<Void> future = sendOffsetCommitRequest(offsets);
client.poll(future, timer);
// We may have had in-flight offset commits when the synchronous commit began. If so, ensure that
// the corresponding callbacks are invoked prior to returning in order to preserve the order that
// the offset commits were applied.
invokeCompletedOffsetCommitCallbacks();
if (future.succeeded()) {
if (interceptors != null)
interceptors.onCommit(offsets);
return true;
}
if (future.failed() && !future.isRetriable())
throw future.exception();
timer.sleep(rebalanceConfig.retryBackoffMs);
} while (timer.notExpired());
return false;
}
//异步提交的核心代码
public void commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) {
invokeCompletedOffsetCommitCallbacks();
//没有corodinator的话直接异步提交offset 提交后注册监听器在消费成功或者失败后调用
//kafka对于异步提交是不支持重试的
if (!coordinatorUnknown()) {
doCommitOffsetsAsync(offsets, callback);
} else {
// we don't know the current coordinator, so try to find it and then send the commit
// or fail (we don't want recursive retries which can cause offset commits to arrive
// out of order). Note that there may be multiple offset commits chained to the same
// coordinator lookup request. This is fine because the listeners will be invoked in
// the same order that they were added. Note also that AbstractCoordinator prevents
// multiple concurrent coordinator lookup requests.
//1.协调器不为空的情况下 先找到协调器
pendingAsyncCommits.incrementAndGet();
lookupCoordinator().addListener(new RequestFutureListener<Void>() {
@Override
public void onSuccess(Void value) {
//成功找到协调器后进行offset提交
pendingAsyncCommits.decrementAndGet();
doCommitOffsetsAsync(offsets, callback);
client.pollNoWakeup();
}
@Override
public void onFailure(RuntimeException e) {
pendingAsyncCommits.decrementAndGet();
completedOffsetCommits.add(new OffsetCommitCompletion(callback, offsets,
new RetriableCommitFailedException(e)));
}
});
}
client.pollNoWakeup();
}
由源码可知:
- 同步提交offset使用while循环在等待,异步提交通过回调监听器的方式;
- 同步提交存在重试机制但是会阻塞后续的offset提交,异步提交没有重试,是否成功立即返回不存在阻塞;
为啥异步不存在重试而同步提交方式可以重试?
例如有两个消息A和消息B分别对应offset为200和300。正常情况下,提交消息A的offset为200后才可以提交300,如果是同步的话消息B会被阻塞,则得等待消息A成功后(包含重试)才会被提交。异步的话如果存在重试的话,消息A失败,消息B成功offset300。消息A再次重试导致之前的offset变成200。
//该方法是向kafka服务器发送拉取数据的请求 并将响应成功的数据放到completedFetches的队列中
public synchronized int sendFetches() {
// Update metrics in case there was an assignment change
sensors.maybeUpdateAssignment(subscriptions);
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
//构建请求参数 最小批次大小1byte 最大50m 超时等待时间500ms
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget())
.rackId(clientRackId);
if (log.isDebugEnabled()) {
log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget);
}
RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
// We add the node to the set of nodes with pending fetch requests before adding the
// listener because the future may have been fulfilled on another thread (e.g. during a
// disconnection being handled by the heartbeat thread) which will mean the listener
// will be invoked synchronously.
this.nodesWithPendingFetchRequests.add(entry.getKey().id());
//添加监听器 当kafka服务器响应成功或者失败时做出对应的处理
future.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
synchronized (Fetcher.this) {
try {
@SuppressWarnings("unchecked")
FetchResponse<Records> response = (FetchResponse<Records>) resp.responseBody();
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
//没有数据直接返回
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.",
fetchTarget.id());
return;
}
//有数据但是处理响应失败 返回
if (!handler.handleResponse(response)) {
return;
}
//
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
for (Map.Entry<TopicPartition, FetchResponse.PartitionData<Records>> entry : response.responseData().entrySet()) {
TopicPartition partition = entry.getKey();
FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition);
//如果获取数据和分区不匹配 则会抛异常
if (requestData == null) {
String message;
if (data.metadata().isFull()) {
message = MessageFormatter.arrayFormat(
"Response for missing full request partition: partition={}; metadata={}",
new Object[]{partition, data.metadata()}).getMessage();
} else {
message = MessageFormatter.arrayFormat(
"Response for missing session request partition: partition={}; metadata={}; toSend={}; toForget={}",
new Object[]{partition, data.metadata(), data.toSend(), data.toForget()}).getMessage();
}
// Received fetch response for missing session partition
throw new IllegalStateException(message);
} else {
//获取消息的偏移量
long fetchOffset = requestData.fetchOffset;
FetchResponse.PartitionData<Records> partitionData = entry.getValue();
log.debug("Fetch {} at offset {} for partition {} returned fetch data {}",
isolationLevel, fetchOffset, partition, partitionData);
Iterator<? extends RecordBatch> batches = partitionData.records.batches().iterator();
short responseVersion = resp.requestHeader().apiVersion();
//最后将从服务器返回的消息数据放到缓存的消息队列中
completedFetches.add(new CompletedFetch(partition, partitionData,
metricAggregator, batches, fetchOffset, responseVersion));
}
}
sensors.fetchLatency.record(resp.requestLatencyMs());
} finally {
//将id从请求中移除 无论成功与否 毕竟不是等待拉取状态
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
try {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
handler.handleError(e);
}
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
});
}
return fetchRequestMap.size();
}
重复消费:
消费者offset自动提交模式,每隔五秒一次提交。当提交的offset为5,在下一次提交offset期间,消费者已经消费到7了。此时消费者挂了重启的时候会从offset为5的位置开始消费,这是6和7就会被重复消费。另外手动提交超时会触发重试造成重复消费。
漏消费:
消费者使用手动提交模式,当offset提交了,但是消费者挂了,未能消费成功 。
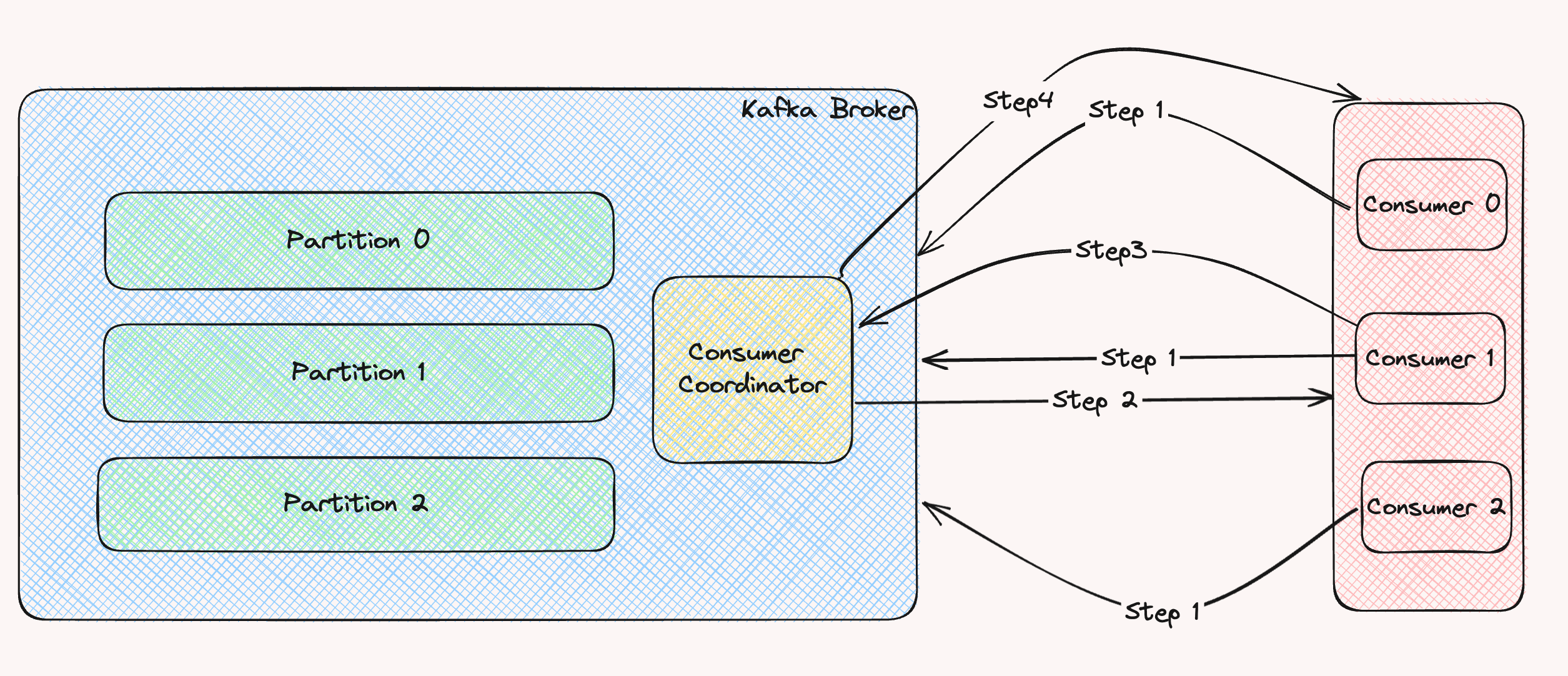
消费者组消费消息的过程:
Step1: 所有消费者向broke发送joinGroup请求;
Step2:选出一个Consumer Leader,先加入组内的即为Leader;Leader制定消费方案;
Step3:Leader发送消费方案给消费协调器;
Step4:消费协调器把消费方案下发给该消费者组中的每个消费者;
每个消费者都会和协调器保持心跳(默认3s),一旦超时 (session.timeout.ms=45s),该消费者会被移除,并触发再平衡:
或者消费者处理消息的时间过长 (max.poll.interval.ms=5分钟)也会触发再平衡。
6.Kafka知识总结
Kafka的幂等性
- 开启幂等性:enable.idempotence=true; 当幂等性开启的时候ack会默认为-1,如果强行设置成0或1时会报错。
- 幂等性是为了保证消息重复多次发送时,只会存在一条数据。但是幂等性是有条件的:
-
只能保证在当前会话中不丢不重
,也就是说当Broke重启后是无法保证的;
- 只能保证单个Partition分区的幂等
-
只能保证在当前会话中不丢不重
- 幂等性原理:引入PID(ProcucerId) 和sequence numbers。 PID用于标识Producer Client,生产者重启后会变化,所以只能保证当前会话的消息幂等,sequence numbers每发送一条消息会递增。
Kafka的事务
Kafka中的消息生产和消息提交offset属于原子性操作,换句话说Kafka的事务中对一批发送多条消息时,要么同时成功要么同时失败。
Kafka事务API使用:
- void initTransactions(); 用于初始化事务Id,该Id是保证整个事务的前提;
- void beginTransaction(); 开启事务;
- void commitTransaction() 提交事务;
- void abortTransaction() 放弃事务,相当于对于事务的回滚;
Kafka事务原理:
为了支持事务,kafka中引入了事务协调器(Transaction Coordinator),
Kafka 集群中也有一个特殊的用于记录事务日志的主题__transaction_state, 内部默认有 50 个 Partition,会根据 Transaction ID 作为分区 Key,并将目标分区 Leader 所在的 Broker 作为 Transaction Coordinator。
在 Kafka 集群中,可以存在多个协调者,每个协调者负责管理和使用事务日志中的几个分区。这样设计,其实就是为了能并行执行多个事务,提升性能。
事务ID引入的作用:引入TransactionId,不同生产实例使用同一个TransactionId表示是同一个事务,可以跨Session的数据幂等发送。当具有相同Transaction ID的新的Producer实例被创建且工作时,旧的且拥有相同Transaction ID的Producer将不再工作,避免事务僵死。
每个生产者增加一个epoch:用于标识同一个事务Id在一次事务中的epoch,每次初始化事务时会递增,从而让服务端可以知道生产者请求是否旧的请求。
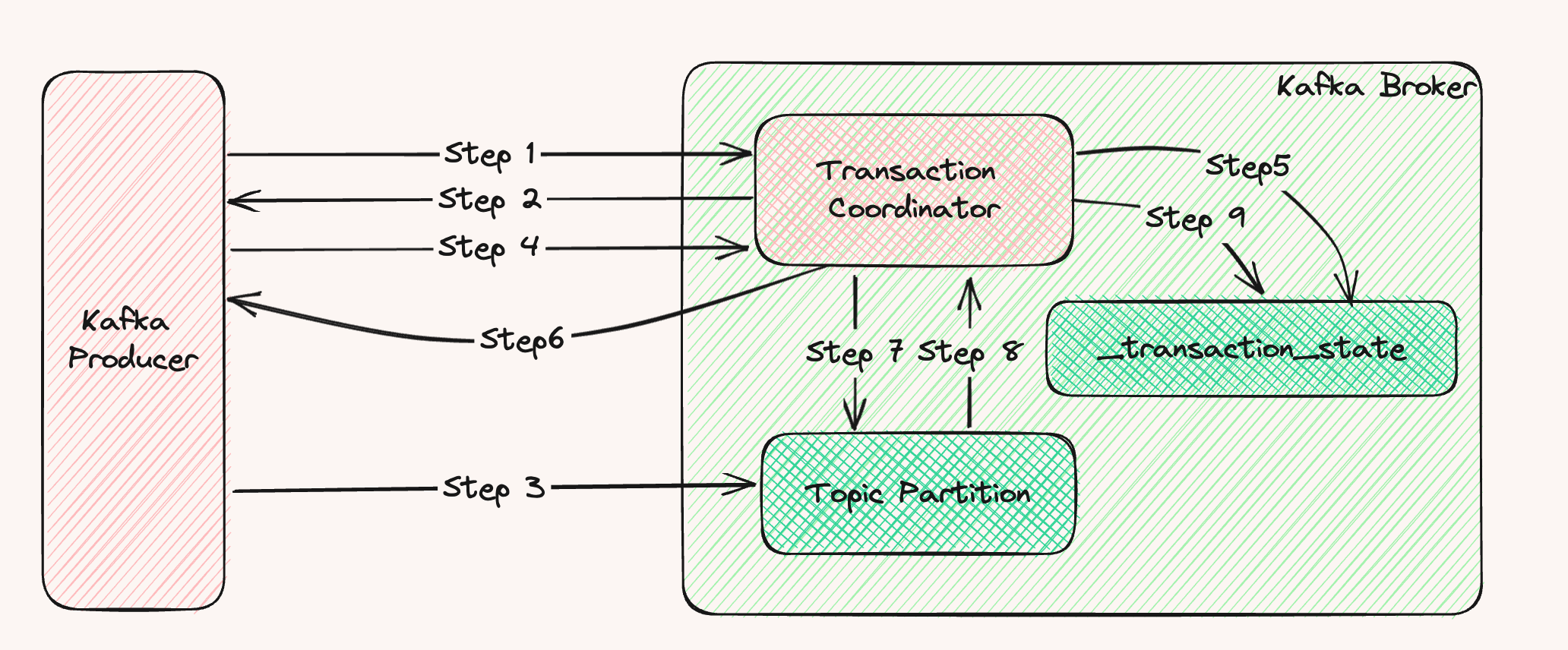
生产者在开启事务之前需要提供一个事务Id(tid), 使用tid请求负载最小的broke,找到该事务对应的transaction coordinator。 (Kafka中会存在多个事务协调器的)
Step1:获取到该transaction coordinator后,获取事务对应PID,和PID对应的Epoch。 Epoch为了防止线程重新复活导致消息重复发送,则当epoch比当前维护的epoch小时会直接拒绝;
Step2:返回PID给生产者;PID在生产者重启后会改变;
Step3:生产者开启事务,发送批量消息到对应的topic,会存在跨topic的消息情况;
Step4:生产者提交事务给事务协调器;
Step5:全部成功会在_transaction_state中添加一条数据事务log并标记为PrepareCommit状态,失败的事务日志是Abort状态;
Step6:向生产者响应,事务成功/失败;
Step7:向事务中消息所在Broke发送marker消息,broke收到消息后得知事务提交;
Step8:Broke响应事务协调器,返回成功;
Step9:事务协调器收到所在Broke的响应成功的数据后,将事务的状态改成Commit状态;
上述描述了Kafka事务的过程,但是Kafka中的事务是有一定的局限性的,问题如下:
1.Step6提交事务成功响应给生产者,但是在Step7发生问题,数据无法消费;
Kafka中的事务是一种理想状态事务,也就是说当在都是成功的情况下是保证原子性,在某一步出现问题无法保证,只能通过不断重试直至成功这种方式来达到目的;
2.在Step7中如果存在5个Broke,但是只有0,1,3,4的Broke响应成功,2因为网络抖动的导致没有响应,但是对于其他4个Broke而言,消息处于可消费状态。
Kafka不能保证强一致性,只能保证最终一致性。如果上述的Broke2挂了,会选举出新的Broke响应,因为事务协调器会不断重试。那如果该topic的所有Broke全部挂了,那么就不能保证事务完整了。所以小编认为kafka中的事务是一种理想型,是存在局限性的,和redis的事务如出一辙,远不及Mysql的事务。
Kafka中Controller的作用:
controller 的任命:所有broker往zookeeper中注册时会创建一个临时序号,序号最小的broker就是集群中的broker
作用:
- 当topic中的leader副本所在的broker挂了,这时需要在isr(in-sync replicate)中选出前面的副本broker作为leader,最前面是因为offset和之前的leader副本偏差最小;
- 当集群中broker新增或者减少,controller了则会通知其他broker进行数据更新;
- 当集群中broker下的分区出现新增和减少,controller也会通知其他broker进行数据更新;
Reblance机制:
当消费者没有指定分区时,会触发reblance,其作用是为了保证消费者负载均衡,触发条件如下:
- 当消费者组新增或减少消费者时;
- 当topic下新增或减少partition分区时;
Kafka中的问题优化:
- 如何防止消息丢失
- 将生产消息到broke的ack机制设置成all或者-1;
- 将消费消息设置成手动提交;
-
消息重复消费
当生产者发送消息后,由于网络抖动,broke没有在重试时间内发送ack到生产者导致生产者消息重新发送。
解决方式:可以使用setNX的命令 插入数据库中
-
顺序消费
发送方得保证消息同步发送,异步会有可能导致前面发送失败的消息重试后排在之前消息的后面;
消费方对需要保证有序的消息只能在相同的分区中,
另外消费者执行时有两种方式:
- 单线程消费;
- 多线程消费得保证顺序消费的消息要在同一个队列中,可以使用hash(key)对队列取余的方式实现;
Kafka中消费方式:
Kafka中采用适应消费者能力的pull模式去消费数据,pull模式在没有消息产生时会产生无效的轮询请求;push的模式的不足之出会导致推过来的消息速率大于消费者消费速率,导致消息处理不及时。
Kafka高效的原因:
-
顺序写日志;
-
分区机制:topic数据分区提高并发访问;
-
零拷贝,DMA,MMAP,页缓存:
零拷贝: 用户态之间不发送数据复制,由内核态直接将数据发送到网卡; DMA:Direct Memory Access ,它可以独立地直接读写系统内存,不需要 CPU 介入,像显卡、网卡之类都会用DMA。 MMAP Memory Map Kafka:使用内存映射技术,直接获取内存地址,将文件直接映射到用户态内存空间,省去了内核态到用户态的拷贝过程;
-
批量数据处理:Kafka 的批量包括批量写入、批量发布等。它在消息投递时会将消息缓存起来,然后批量发送 同样,消费端在消费消息时,也不是一条一条处理的,而是批量进行拉取,提高了消息的处理速度;
-
数据压缩:Gzip、Snappy、Lz4 和 Zstd,推荐使用Snappy算法。
Kafka采用 Leader Epoch的作用:
Leader Epoch 是一个递增的序列号,用于标识每个领导者(leader)周期的唯一性。在进行副本重新分配选主时,都会递增Leader Epoch中的值,确保新的领导者周期和老的周期值不同。尤其是在新的leader副本选举时,选出的Epoch要大于之前的Epoch的值,防止旧的周期中假死导致与新领导者冲突;
Kafka不支持延时队列的原因:
Kafka的设计初衷是低延迟高吞吐量数据流处理,延时队列需要对数据保存一段时间后触发。
- 实时性:等待时间会导致消息的延迟,违背kafka实时性的初衷;
- 顺序保证:kafka可以保证分区顺序,引入延时消息会导致复杂性;
- 存储:延时队列需要在队列中存储延时消息,如果消息很多都是长时间延迟就会导致数据压积。
Kafka日志存储
Kafka中每个Partition对应一个日志文件,producer生产的数据会被不断追加在log文件末端,为了防止log文件过大不利于数据查找,Kafka采用了分片和稀疏索引思想。
每个分区可分成多个Segment,每个Segment包括:1.log日志,用于存储消息数据;2.index日志,偏移量索引日志;3.timeindex时间戳索引的日志;其中index和log日志文件是以当前文件第一条消息来命名的。
index日志是稀疏索引,当往log文件中写入4kb数据时,会往index日志中写入一条数据。log.index.interval.bytes=4kb(默认)
index日志中写入的相对offset,绝对offset是根据文件名的大小加上相对offset。使用相对offset减少占用的空间。
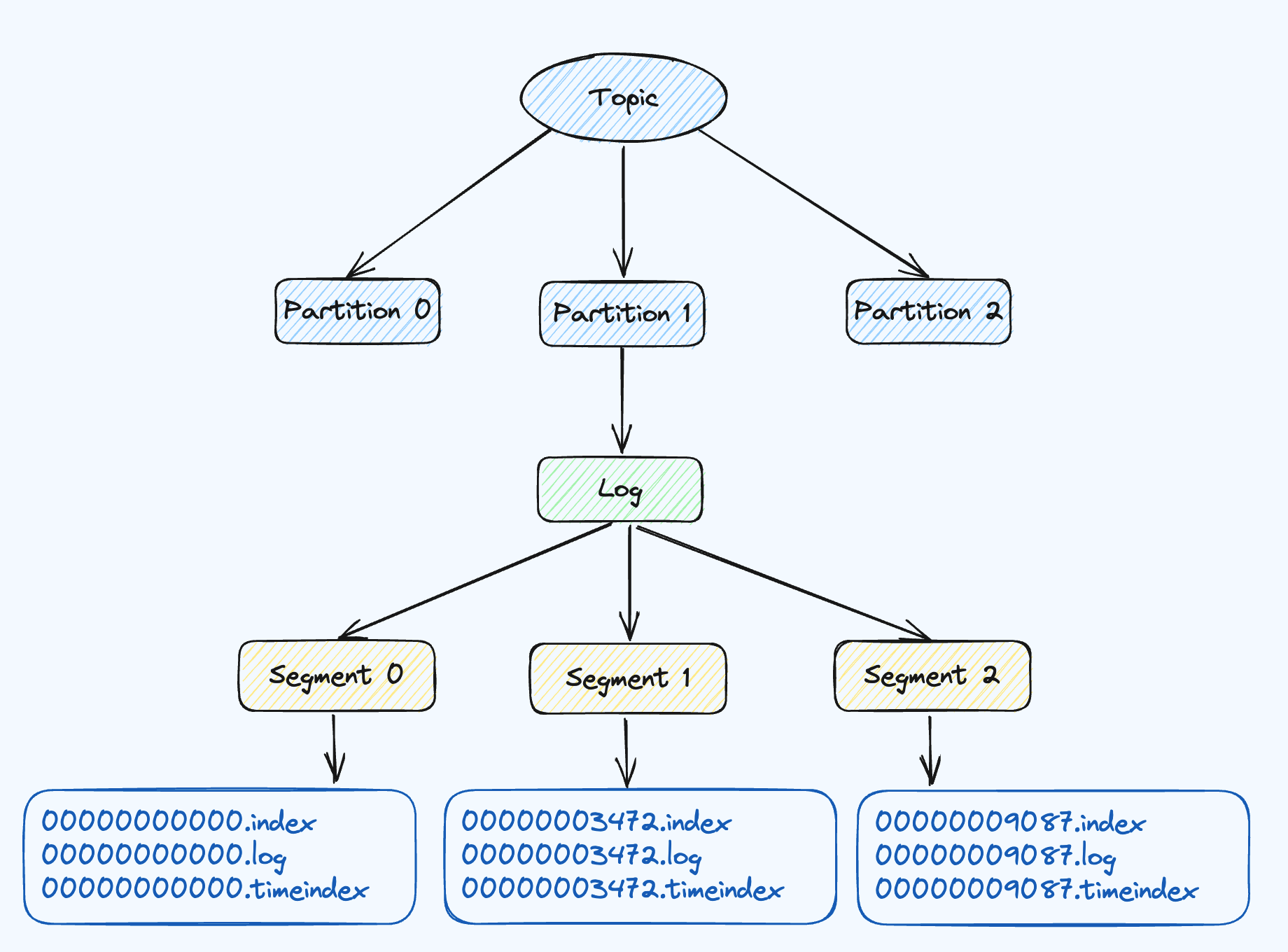
根据上述描述,index文件是稀疏索引,所以在查找offset为3548这样的消息日志,先会去index/timeindex的日志文件中查找。举一个详细的例子
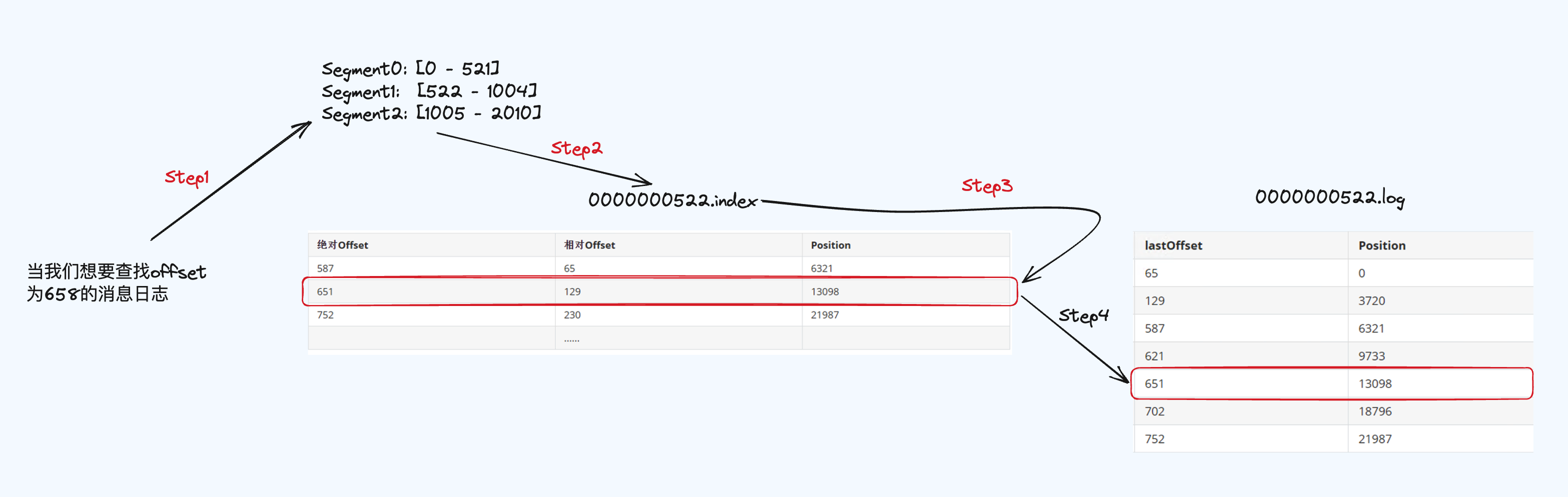
Step1:根据offset为658定位到Segement1,
Step2: Segment1以522开头的index文件;
Step3: 图中显示了绝对offset,实际上存储的时候是没有的根据文件名的offset加相对offset得出来的,658大于651小于752,则找到position为13098;
Step4: 根据Position为13098去522开头的log文件中找到651的数据,实际上该数据还是不是真正的消息日志,继续往下找。
基于时间戳的功能 1 根据时间戳来定位消息:之前的索引文件是根据offset信息的,从逻辑语义上并不方便使用,引入了时间戳之后,Kafka支持根据时间戳来查找定位消息 2 基于时间戳的日志切分策略 3 基于时间戳的日志清除策略
7.Kafka中选举机制
1. Controller控制器选举
Controller 任命:所有broker往zookeeper中注册时会创建一个临时序号,序号最小的broker就是集群中的broker,其他的broker在启动时也会在zookeeper中创建临时节点,如果zk已经存在了节点,那么就会收到一个异常,认为已经有节点存在了,这时候就在zk中注册一个watch对象,用于接收来自zk的变更。
Controller变更:由于网络原因导致controller和zk失去连接时,其他broke可以通过watch对象收到通知,这时都会去zk来注册自己,如果有一个注册成功,同样其他的就会收到一个异常,和上述一样。[旧版本]
2. Partition副本Leader选举机制
副本leader的选举是由controller来完成,controller会在ISR中选出第一个作为该topic的分区的Leader副本。因为ISR中排在前面的副本是和主副本offset的差距最小的。
3. 消费者组选举 GroupCoordinator需要为消费组内的消费者选举出一个消费组的leader,这个选举的算法很简单,当消费组内还没有leader,那么第一个加入消费组的消费者即为消费组的leader,如果当前leader退出消费组,则会挑选以HashMap结构保存的消费者节点数据中,第一个键值对来作为leader。
4. 消费者组协调器选举
Coordinator是Kafka中的一台broke
Coordinator的选择:一个消费者组是存在一个groupId,先通过对这个groupId进行hash得到一个值,再根据这个值对_consumer_offset主题的分区数(默认50)取模,取模后所对应的分区所在broke作为该消费者组的Coordinator。
Coordinator会在消费者组中选举出消费者Leader,该leader主要角色是制定消费方案并同步给Coordinator。Coordinator会将消费方案同步给各个消费者
每个消费者和Coordinator保持心跳(默认3s),一旦超时(默认45s)就会把该消费者剔除然后进行重平衡
5.Reblance机制:
当消费者没有指定分区时,会触发reblance,触发条件如下:
- 当消费者组新增或减少消费者时;
- 当topic下新增或减少partition分区时;
6.Kafka中的问题优化:
- 如何防止消息丢失
- 将生产消息到broke的ack机制设置成all或者-1;
- 将消费消息设置成手动提交;
-
消息重复消费
当生产者发送消息后,由于网络抖动,broke没有在重试时间内发送ack到生产者导致生产者消息重新发送。
解决方式:可以使用setNX的命令 插入数据库中
-
顺序消费
发送方得保证消息同步发送,异步会有可能导致前面发送失败的消息重试后排在之前消息的后面;
消费方对需要保证有序的消息只能在相同的分区中,
另外消费者执行时有两种方式:
- 单线程消费;
- 多线程消费得保证顺序消费的消息要在同一个队列中,可以使用hash(key)对队列取余的方式实现;