这周忙到飞起,采用轮流值班制解决测试环境的问题。运气好的话啥事没有,运气不好忙到爆炸。这周我就是属于后者的情况,从周三一直排查问题,到周五上午,一堆需求没有做。唉!就感觉每天的时间过得真快,不过查问题还是很锻炼人的,至少这次排查学习到了一些。
1. 问题表现
测试人员反应某个功能异常,然后去对应的应用使用top命令看了一下,果然cpu打满了,如下图所示:
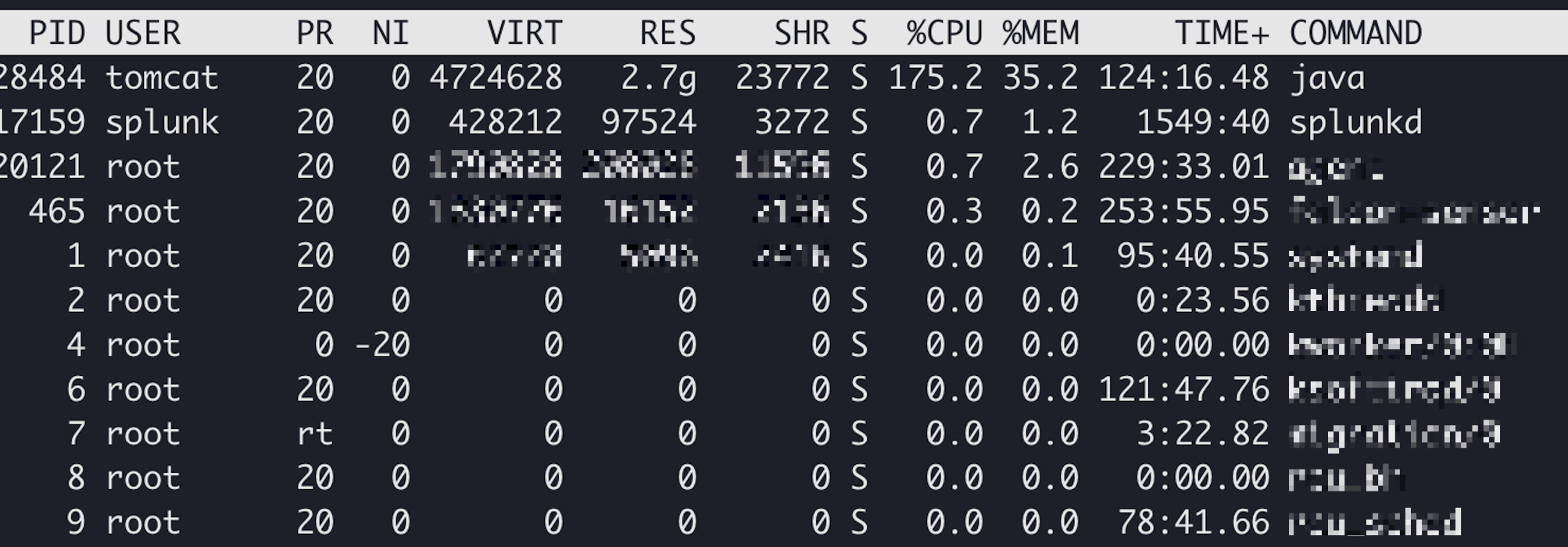
然后使用top -Hd {pid}查看进程内的线程情况,可以确定是那一个线程。
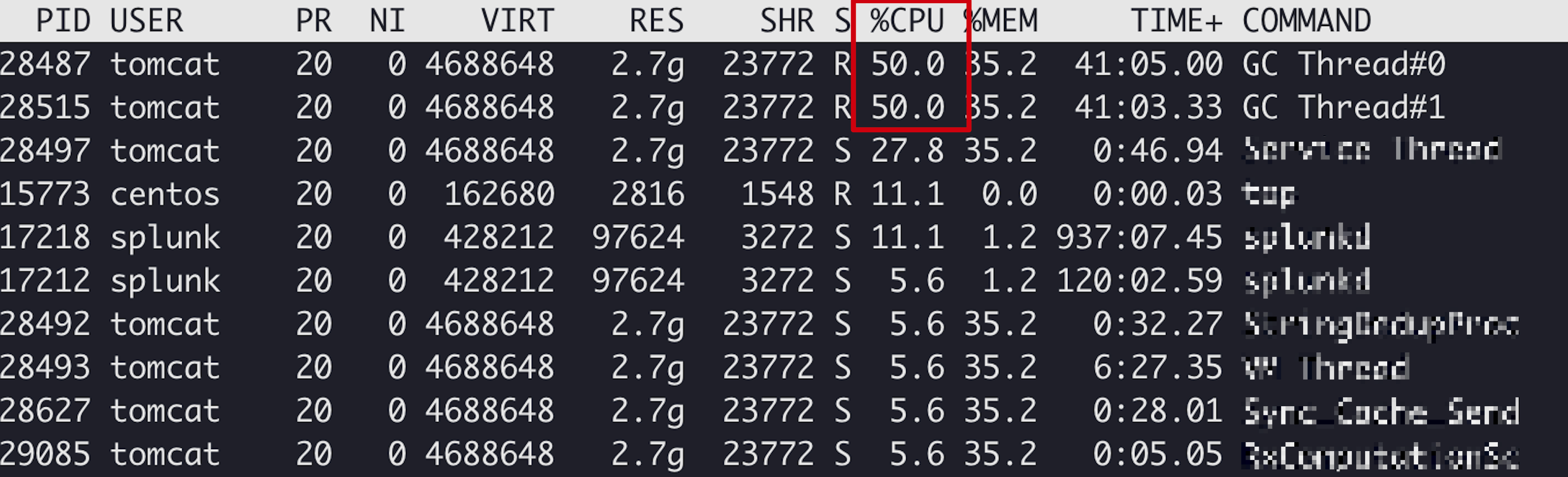
通过线程的数据发现有两个GC线程都达到了50%,此处很明显是产生异常GC情况,两种情况:1.大对象数据产生的速度快于GC速度;2.内存泄漏,对象无法回收;
这里使用了两个线程对对象进行回收。
再使用查看jstat的命令查看每秒GC的数据:jstat -gcutil {pid} 1000
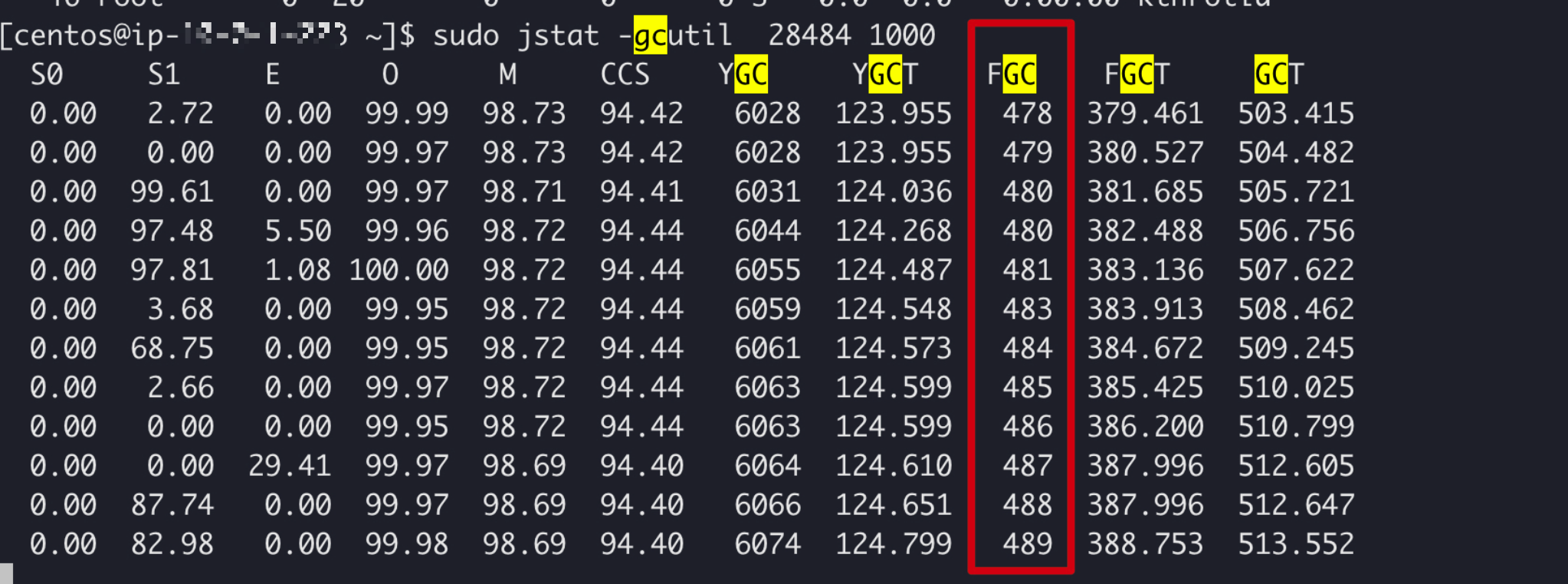
由上图可知,基本每秒一次Full GC,明显有问题了。
2. 问题分析
2.1 收集数据
其实出现这种情况基本上需要把整个进程数据给dump下来,如果是某一个用户线程的cpu高,我们可以在线查看该用户线程的数据,可以根据用户线程的数据来定位代码问题。这种情况下不行,于是开始dump线程数据:
- jmap -dump:live,format=b,file=~/dump.hprof $pid
由于在服务器上需要下载到本地电脑分析,所以为了加快下载先压缩后下载,该文件是不小的;
压缩文件命令:tar -zcvf dump.tar.gz dump.hprof
下载文件命令:scp -i ~/.ssh/{公钥文件} {服务器用户名}@{ip}:/tmp/dump.tar.gz ./
2.2利用工具分析
小编使用VisualVM工具来分析的,当然工具很多,熟悉哪一个用哪个。
将上述的dump文件加载到VisualVM工具中使用,
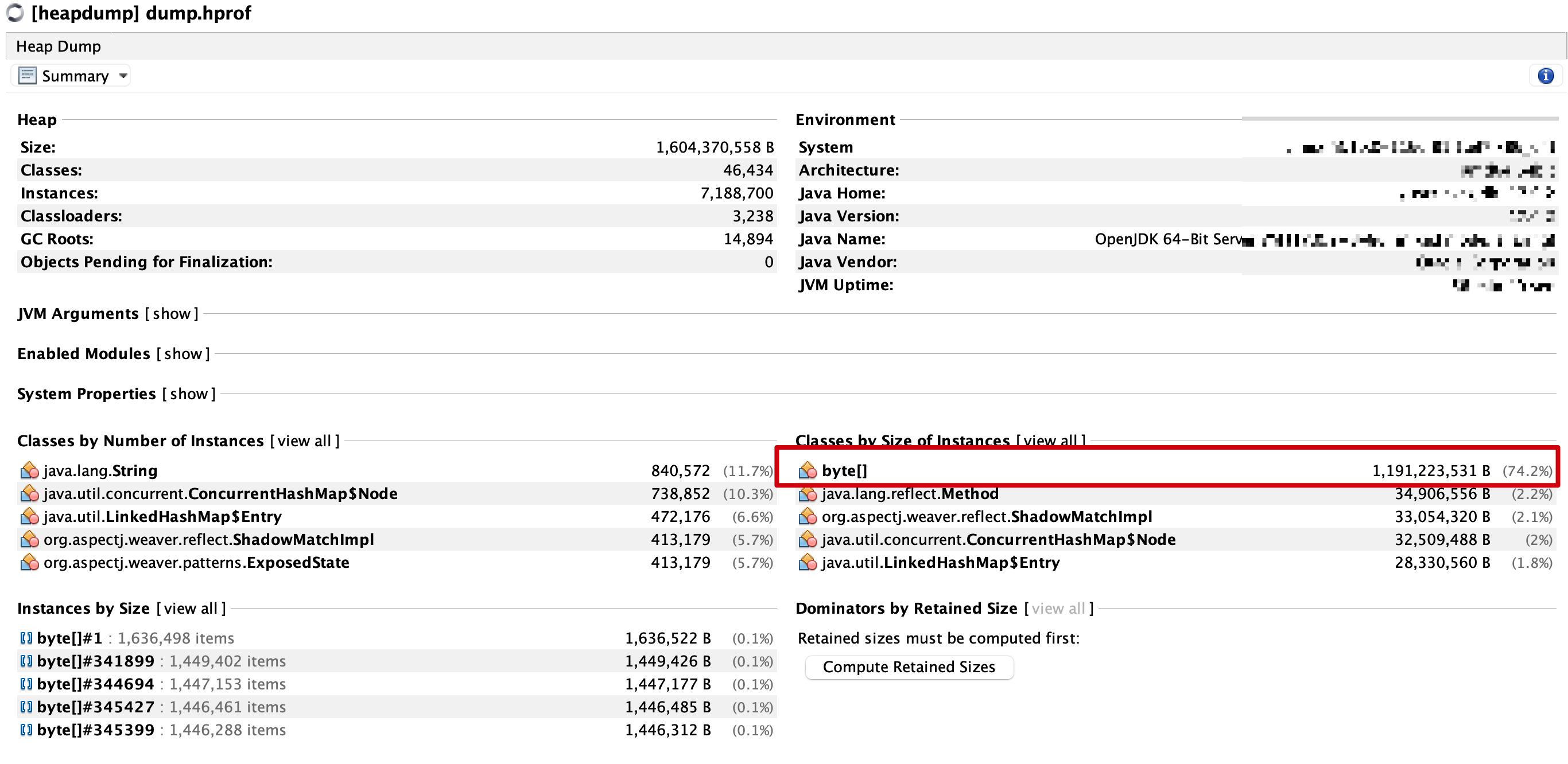
上述有个实例显示的很异常,所有的byte[]数组占用74.2%的空间,可以点击对应的byte数组查看详细信息。
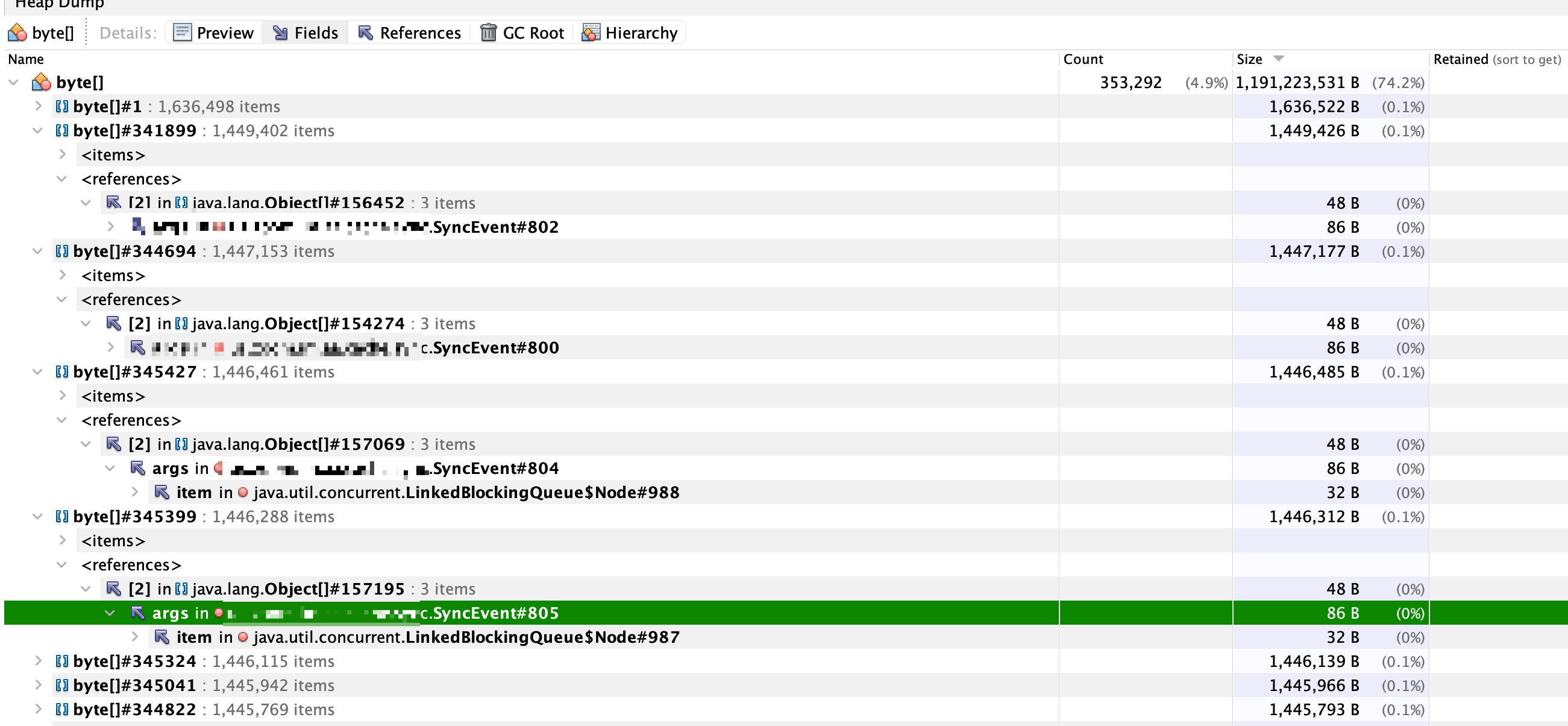
上述那个SyncEvent对象是使用双A同步数据的对象,而且是底层的依赖包,主要对于Redis的数据从A1节点发送到A2节点对数据回放。所以查这个对象没有意义。很重要的一点是:这个对象可能会和业务构建关联,因为只有业务会触发Redis的数据改变进而消息发送,基于此我们要根据这个对象将项目中的某个业务关联起来,那么离真相又近了一步。
第一种: 下载字节数组对象查看,检查是否和业务存在关联的数据;
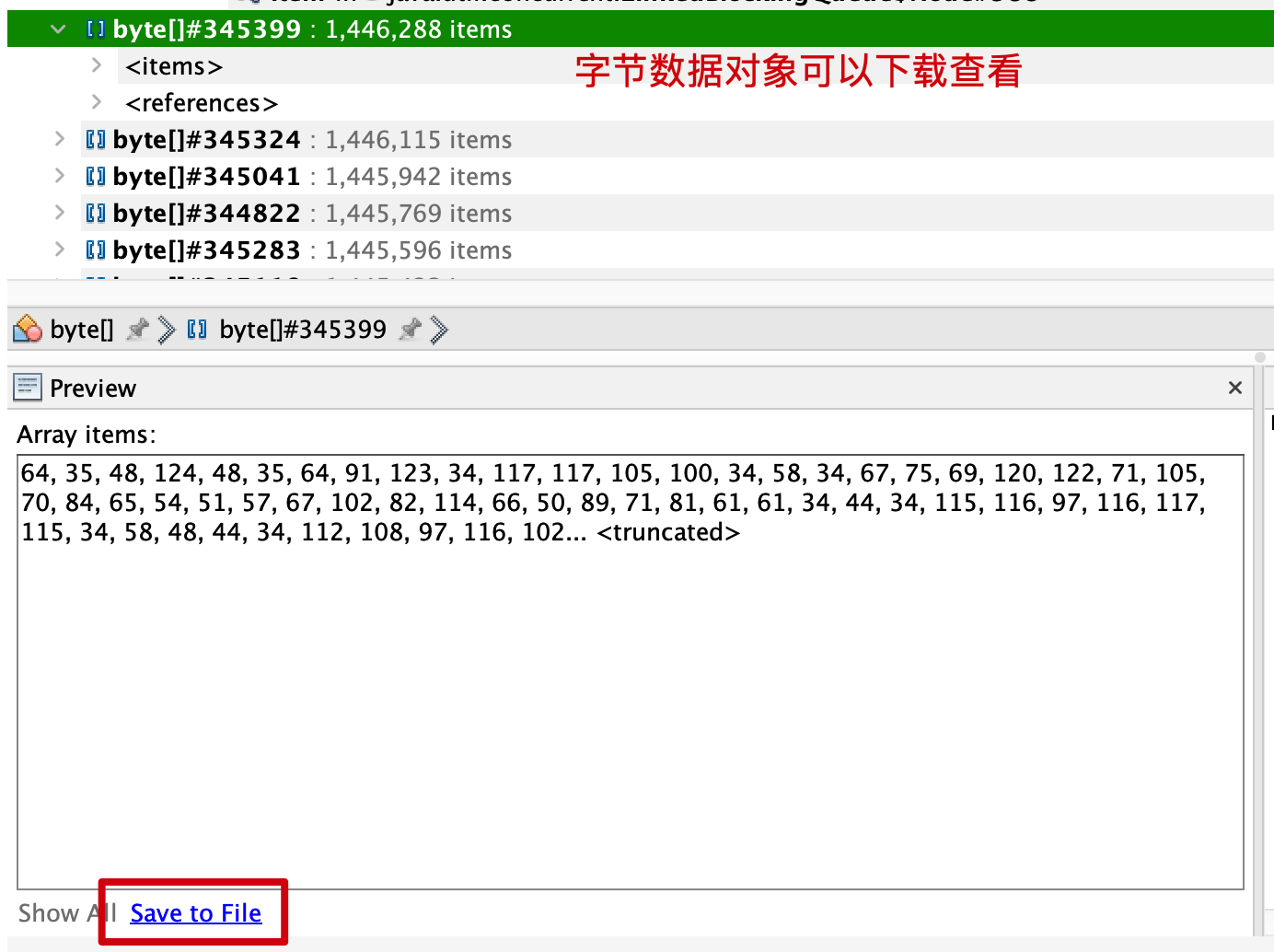
第二种:我点开了SyncEvent对象查看到
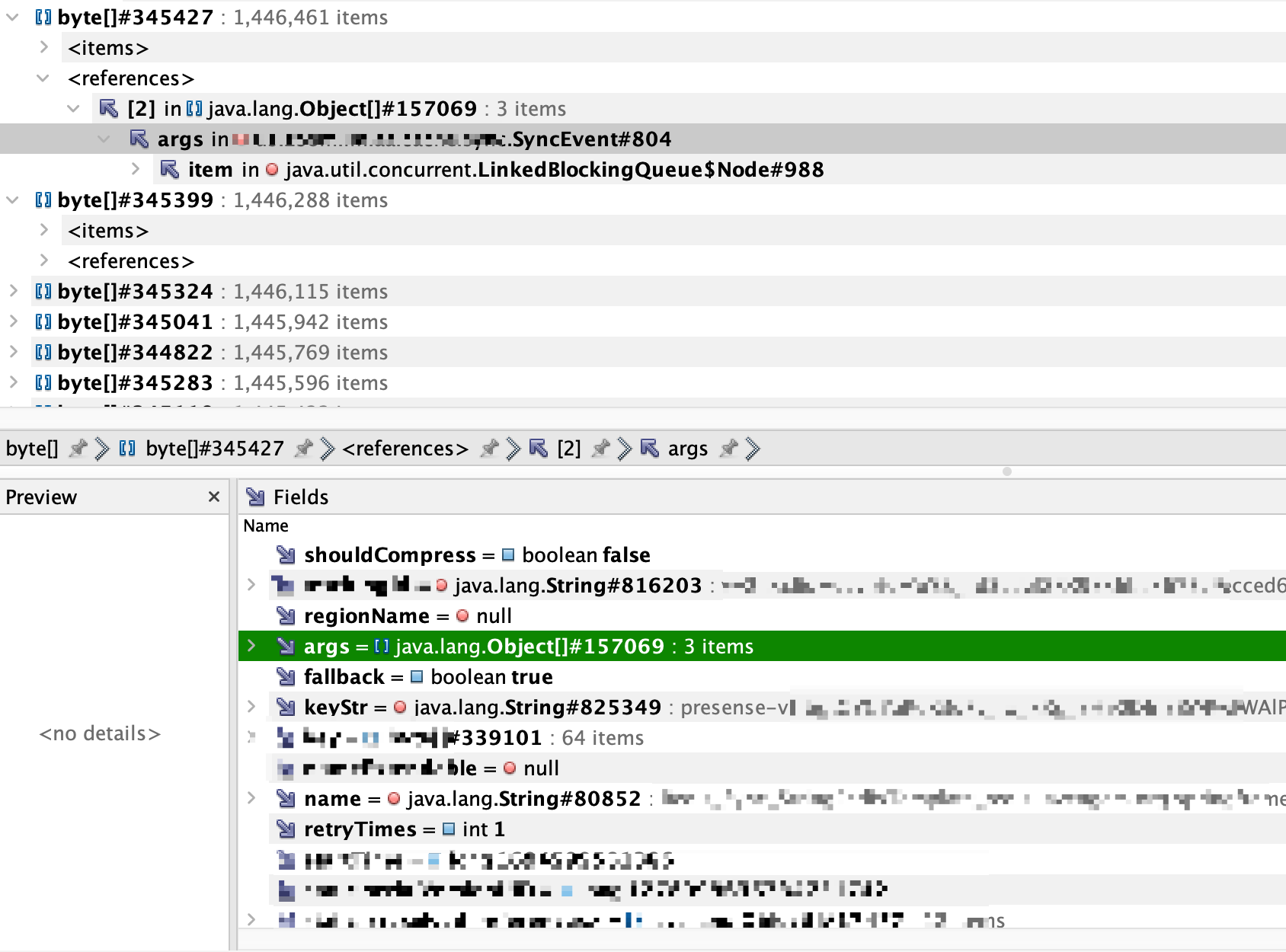
由上图可知:我们找到了和业务相关的key,那个keyStr是同步Redis的业务key,这个key就是业务产生的key,于是在代码中搜索presense这个前缀定位到对应的代码。
再根据第一种方式查看了item的对应数据,全是相同的数据,唯一时间戳不一样,第一反应就是有人在压测,不然一个正常用户怎么会产生那么多数据。数据的产生也是因为代码存在隐患,具体逻辑是:
当一条消息过来就会将当前的key中的数据取出来,该数据是一个list,再将这条消息数据追加到这个key中,重新塞回到redis对应的key,这时会触发redis的数据同步到A2,把这个追加后的数据放到队列中进行发送。由于消息越来越多,导致这个list大小越来越大。在同步这个list数据到A2的时候,消息数据过大无法消费,导致消息一直积压在这个BlockingQueue中,此时JVM也无法回收该对象,因此造成了内存泄漏。
2.3问题解决
当时我们尝试去重启该应用发现是没有用的,找到问题原因后,我们把MQ中积压的消息offset调整到lastest,也就是丢弃之前生产者产生的消息,然后重启了服务就可以正常工作了,后来我去查看了一下日志,发现很有规律性。
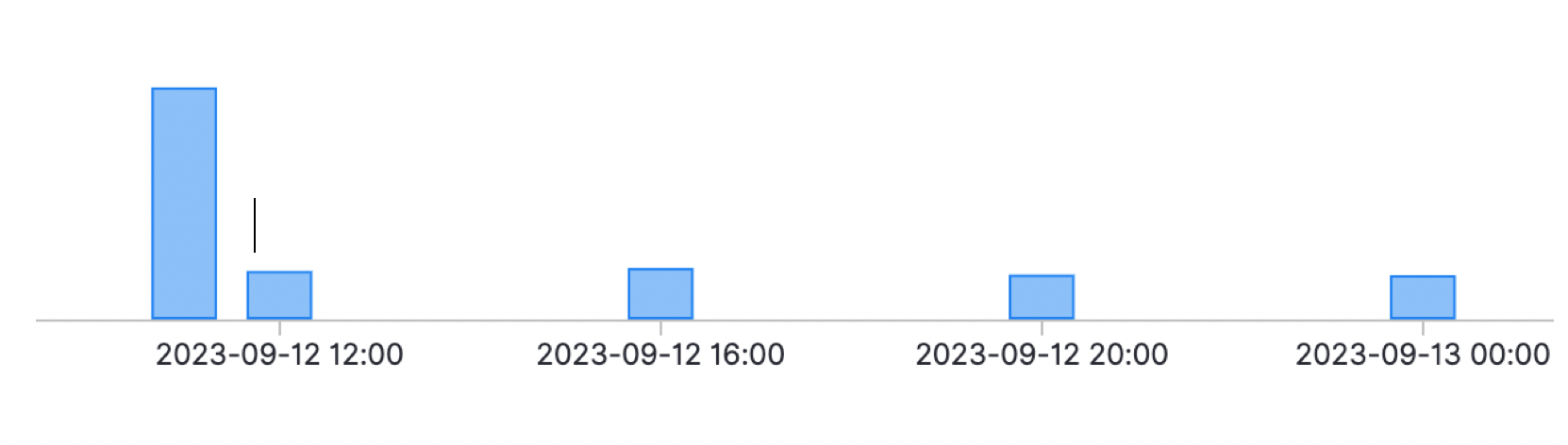
由上图所示:
第一个长柱是压测开始的时间,大对象还没有形成,因此可以正常消费;
第一个短柱表明问题已经发生阻塞,是发生了服务的一次重启,队列里面的消息数据在重启后被清除了,这时上游积压的消息又过来重新获取那个大的List添加一条数据塞回到redis中,这时redis需要同步该数据所以该大对象扔到了队列中,无法消费,所以又会产生内存泄漏,这时无法再继续消费上游的消息。
然后后续的短柱和第一个短柱一样 都是重启导致的原因。
3.问题总结
上述的原因是因为压测导致的,但是代码也存在一定的隐患,总结如下:
-
尽量避免在redis中获取一个大对象数据,可以采用增量的方式而不是全量的方式,文中的隐患就是有小伙伴取出来jsonString对象然后在后面追加一条,再转成String存进去,这样随着用户的频繁操作会产生一个大的对象;
-
使用VisualVM去分析这种问题的时候,找到可疑的对象后一定要关注该对象和业务之间的关系,通过该关系来定位到该项目中的问题;