1.初衷
在项目开发中,通常我们会将某个完整对象存储在缓存中,但很少会对分页数据做缓存处理。 在设计这个组件之前,基本没有专门处理分页缓存的方案。
由于 Redis 提供了丰富的数据结构,我们选择了ZSet(有序集合) 来支持分页场景。
✅ 为什么选择 ZSet?
分页数据通常要求 有序,需要按某个指标(如创建时间)排序。
ZSet保证了数据的有序性;- 可将排序字段(如创建时间戳)作为
score; - 利用
rangeByScore等命令获取分页数据,高效简洁。
2.分页缓存方法论
2.1初级应用
以订单数据作为例子。
💡 场景:商家需要查看某产品的所有订单,按创建时间倒序排列。
📌 数据结构设计
| 项目 | 内容说明 |
|---|---|
| ZSet Key | 产品 ID(例如:product:12345) |
| ZSet Value | 订单 ID(orderId) |
| ZSet Score | 创建时间(时间戳) |
使用 API:
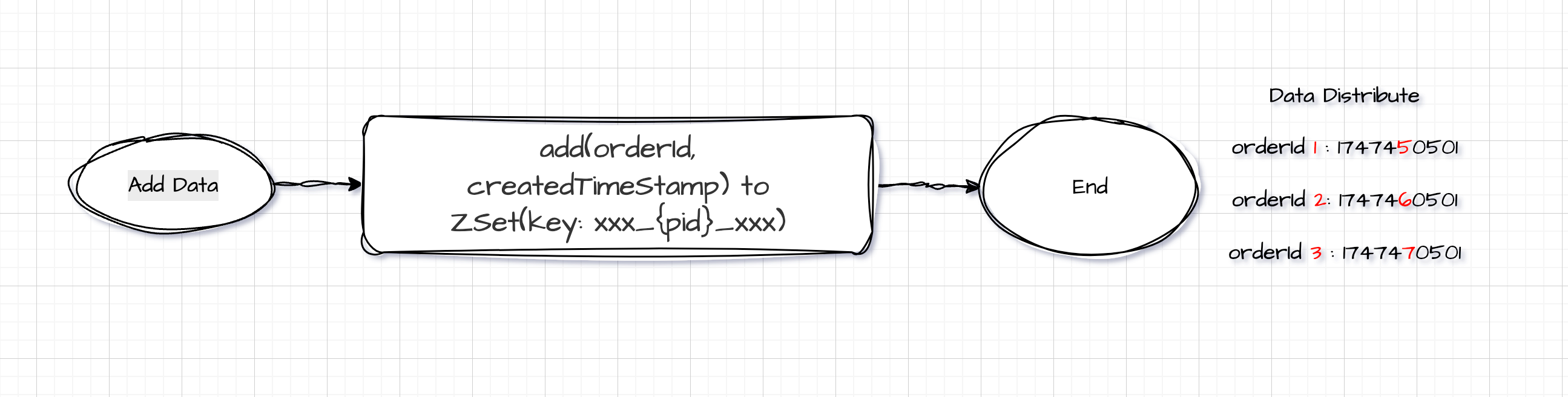
ZSetOperations.add(K productId, V orderId, double createdTime);
订单详情数据本身仍以
orderId为 key 缓存在 Redis 中,分页查询结果中拿到一批 orderId 后,可调用multiGet()一次性获取完整详情。
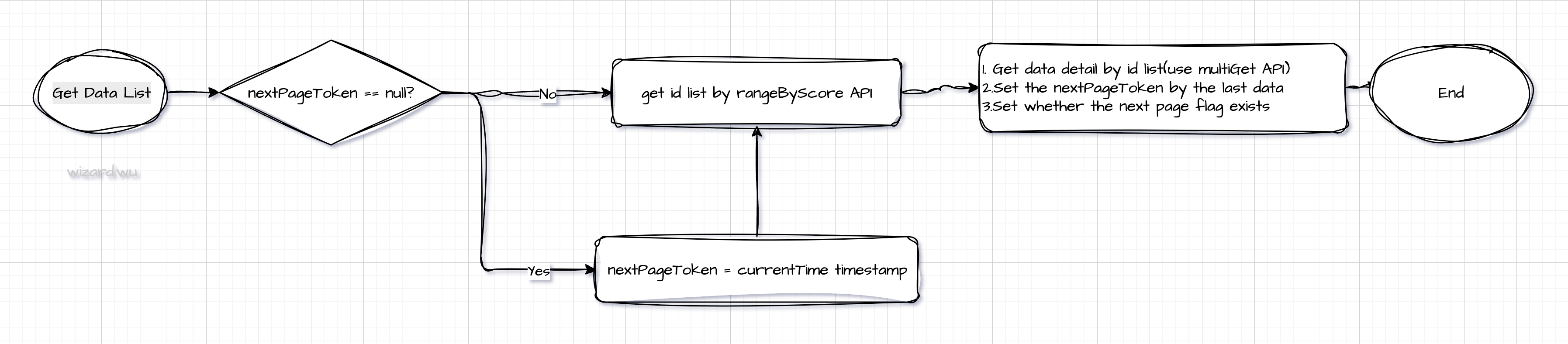
📥 数据获取流程:
- 使用
rangeByScore(productId, min, max, offset, limit)获取订单 ID 列表; - 使用
multiGet(orderIds)获取详情; - 返回结果。
Note:
nextPageToken的构建: 如果pageSize大小为10时,在去获取id数据时一定要获取11条,因为要根据最后一条的数据构建成nextPageToken,但是返回的时候只返回10条数据(需要去除第11条)和对应的nextPageToken;另外可以根据返回的数据有否为11条来决定next page flag
在存储过程中使用时间戳作为score时,如果数据库字段对该字段只精确到秒的话会出现获取不到下一页数据的异常,造成一个原地踏步的情况。例如在并发很高的系统一秒内产生三十条订单数据,此时每一批获取数据为20条,这就导致nextPageToken始终是相同的,在获取下一页数据时始终拿着这个时间戳获取数据导致一直原地踏步。(脚本批量插入数据时会导致created_time相同)
解决方法: a.提高数据库时间戳字段的精确度;b.增大查询的pageSize大小,但是该方法只能降低概率不能完全避免;
❌ 多字段分页问题
若需要支持按多个字段分页(如开始时间、结束时间、更新时间),每个字段都需建立独立 ZSet,会带来数据冗余。
2.2进阶应用
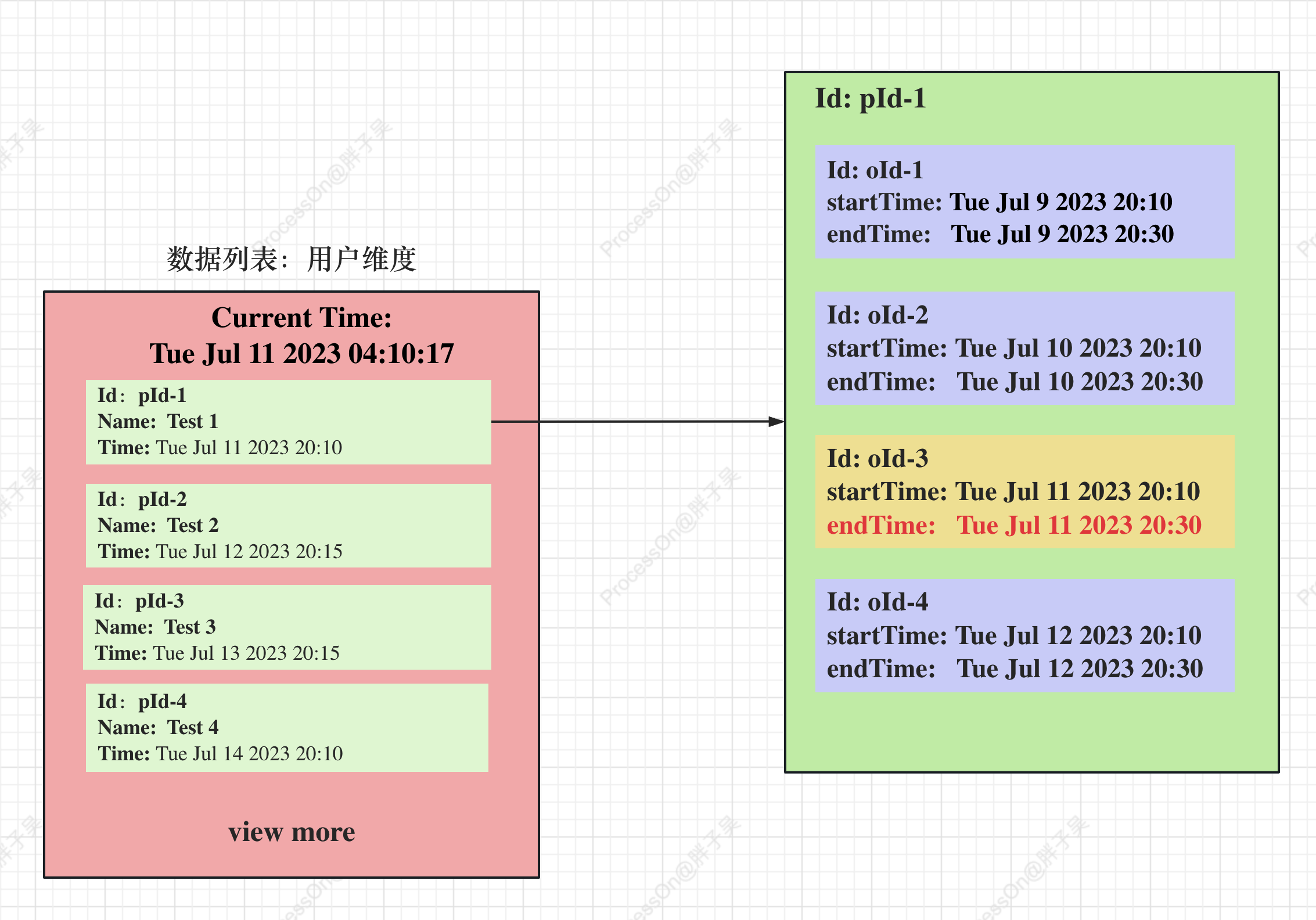
进阶和初级主要不同点在于在存入数据,初级的话主要存储的是主键orderId, 进阶的话主要存储的是一个对象,根据rangeByScore来批量获取对象,再根据对象计算出来所对应的id,从而能实现批量获取数据。如下如所示,pId-1中会有多条数据满足查询条件,我们只希望显示未来发生的第一条,这时我们需要根据pId-1进行一个分组然后取出第一条即可。所以存储的对象不仅包含oId还要包含pId,这就形成了一个对象。
3.分页缓存实现
1.定于数据顶层接口,方便送入数据到Zset集合中:
public interface PageCacheData<T> {
//此处使用泛型主要是为了在进阶应用中使用对象作为key,通常情况下而言使用String类型
T retrievePayload();
//用于获取对象中的某个参数作为排序key,也就是Zset中的Score
double retrieveToken();
}
2.写入某条数据
public <T> boolean addData2Page(String key, PageCacheData<T> pageCacheData) {
try {
//将payload中的数据序列化成String存入,通常情况下就是一个String类型的数据
String payloadString = objectMapper.writeValueAsString(pageCacheData.retrievePayload());
return Boolean.TRUE.equals(redisTemplate.opsForZSet().add(key, payloadString, pageCacheData.retrieveToken()));
}catch (Exception e){
}
return false;
}
3.获取数据
/**
* 1.当使用分页查询时,nextPageToken要设置成最小值Double.NEGATIVE_INFINITY,直接使用offset和pageSize即可
* 2.当使用view more查询时,offset要设置成0,直接使用nextPageToken和pageSize
* 但对于nextPageToken而言的话,要取上一条数据的最后一条数据的时间戳
* @param key
* @param nextPageToken
* @param offset
* @param pageSize
* @return
* @param <T>
*/
public <T> Collection<T> getPayloadByToken(String key, double nextPageToken, int offset, int pageSize){
Set<String> set = redisTemplate.opsForZSet().rangeByScore(key, nextPageToken, Double.POSITIVE_INFINITY, offset, pageSize);
//反序显示
//Set<String> set = redisTemplate.opsForZSet().reverseRangeByScore(key, Double.NEGATIVE_INFINITY, startToken, offset, pageSize);
try {
return set.stream().map(value ->{
try {
return objectMapper.readValue(value, new TypeReference<T>() {});
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}).collect(Collectors.toList());
}catch (Exception e){
}
return Collections.emptyList();
}
上述获取的数据是id数据,为了获取到详细数据,还需要根据id来获取对应的详细数据
4.获取分页数据的详细数据
public <V> Collection<V> getPageData(String key, double startToken, int offset, int pageSize){
//调用第三条中的方法获取ids数据
Collection<String> ids = this.getPayloadByToken(key, startToken, offset, pageSize);
//根据ids数据来获取每条详细数据
List<String> objList = redisTemplate.opsForValue().multiGet(ids).stream().filter(Objects::nonNull).collect(Collectors.toList());
//反序列化数据
return objList.stream().map(order -> {
try {
return objectMapper.readValue(order, new TypeReference<V>() {});
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}).collect(Collectors.toList());
}
5.结果呈现
a). 通过页码显示数据
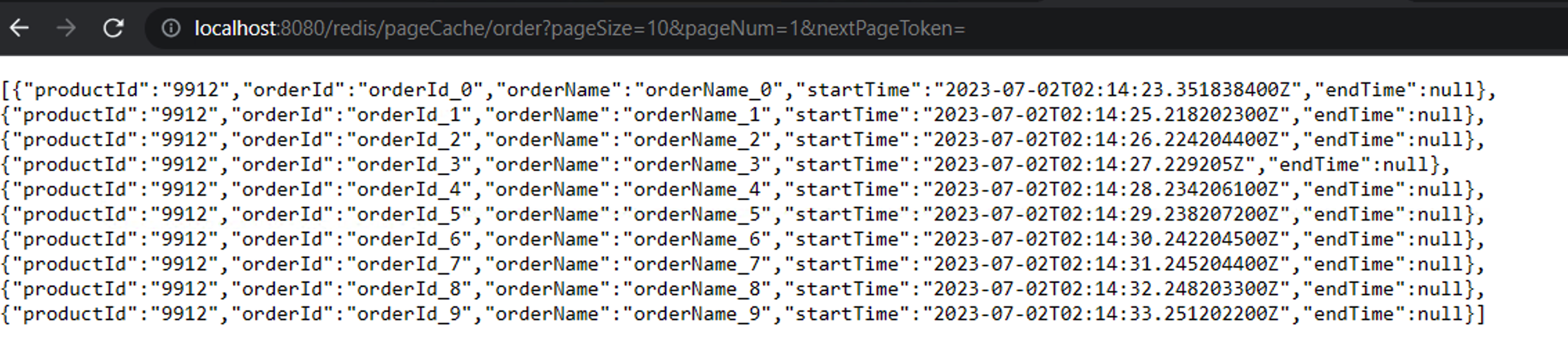
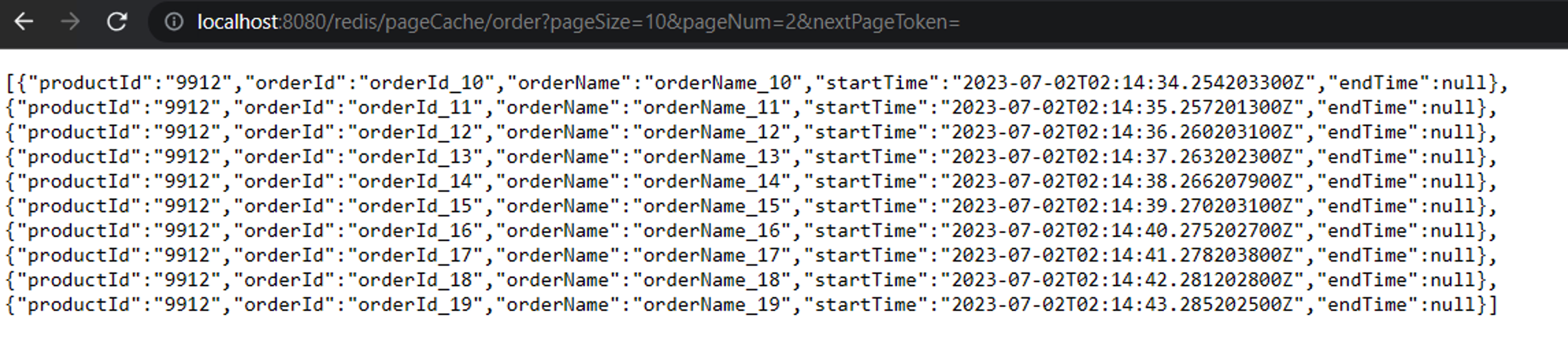 上述分别显示了第一页第二页的数据,通过pageNum分别是1和2获取,每一页10条数据。
上述分别显示了第一页第二页的数据,通过pageNum分别是1和2获取,每一页10条数据。
b). 通过nextPageToken显示数据,此时pageNum要设置成1并且不要改变,否则影响返回数据正确性
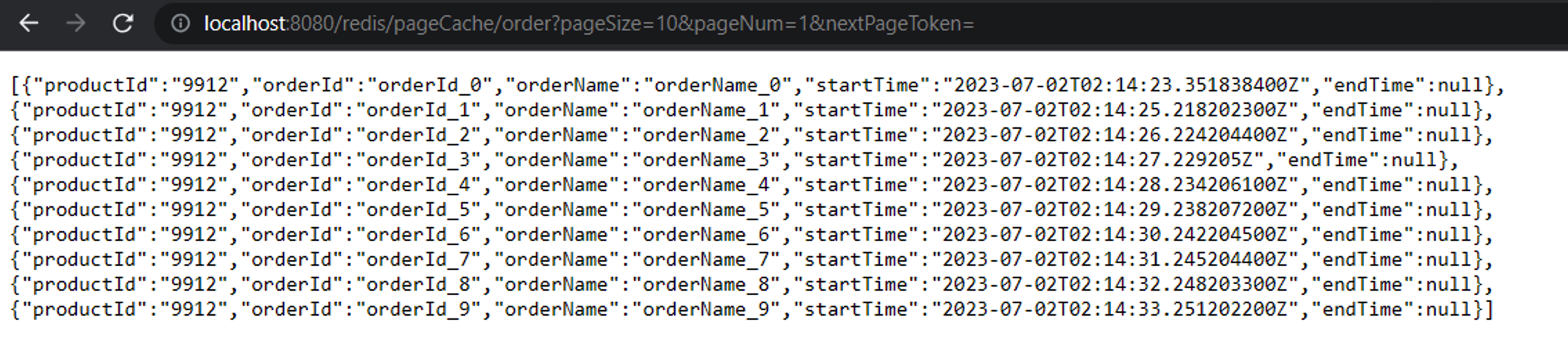
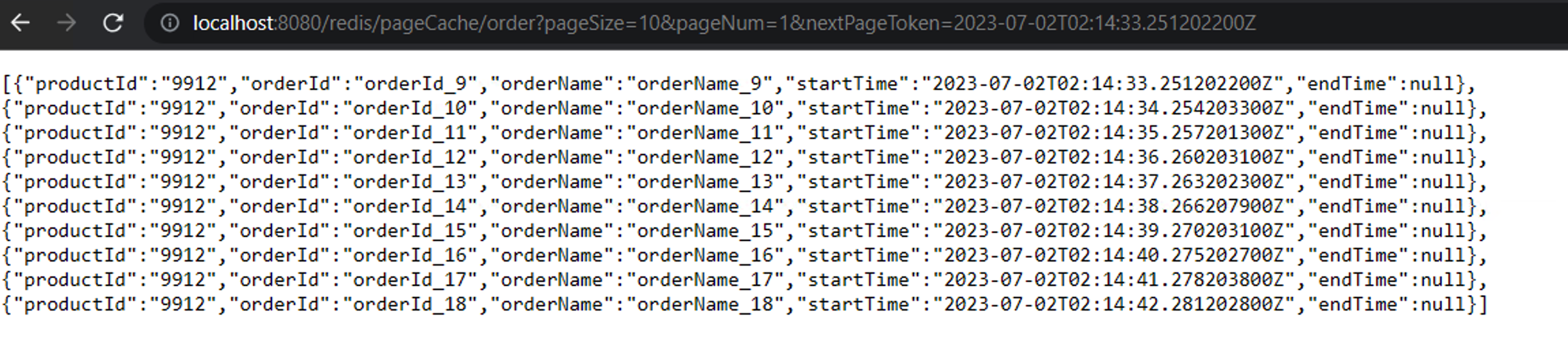
上述是我直接拷贝了第一页最后一条数据的startTime作为nextPageToken返回数据的,你会发现第一页和第二页均会包含相同的orderId_9这条数据,这问题不大。在实际使用中,返回的数据是后端会帮你构建一个nextPageToken进行返回,如果需要到下一页,前端直接使用这个nextPageToken即可获取下一页数据。
Note:-
nextPageToken的构建,如果pageSize大小为10时,在去获取id数据时一定要获取11条,因为最后一条的数据需要构建成nextPageToken,但是返回的时候只返回10条数据和对应的nextPageToken;
-
在存储过程中使用事件戳作为score时,如果数据库字段对该字段只精确到秒的话会出现获取不到下一页数据的异常。例如在并发很高的系统一秒内产生三十条订单数据,此时每一批获取数据为20条,这就导致nextPageToken始终是相同的,在获取下一页数据时始终这个时间戳获取数据导致一直原地踏步。(脚本批量插入数据时会导致created_time相同)
解决方法: a.提高数据库时间戳字段的精确度;b.增大查询的pageSize大小,但是该方法只能降低概率不能完全避免;
4.总结
本文讲述了使用redis的zset的数据类型实现分页缓存,在zset中存储主键id,再根据主键id批量获取数据返回,支持分页查询和page token形式的查询。
可以优化的点:
- 在zset的数据过期时,提供一个lambda表达式给业务方,主要用于维护整个页面的主键id集合;
- 提供正序和反序的方式查找;
- 数据量大时采用数据分片;将productId_9912-0, productId_9912-1;
- 在通过ids获取详细数据时,数据可能不在redis中,需要提供一个函数让业务方灵活获取自己对应数据;